Контекстные менеджеры в python
Содержание:
Найти все страницы, где есть заданный текст
Этот скрипт довольно практичен и работает аналогично . Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат заданную строку поиска. Страницы загружаются одна за другой и с помощью метода обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на :
import fitz
filename = "source/Computer-Vision-Resources.pdf"
search_term = "COMPUTER VISION"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
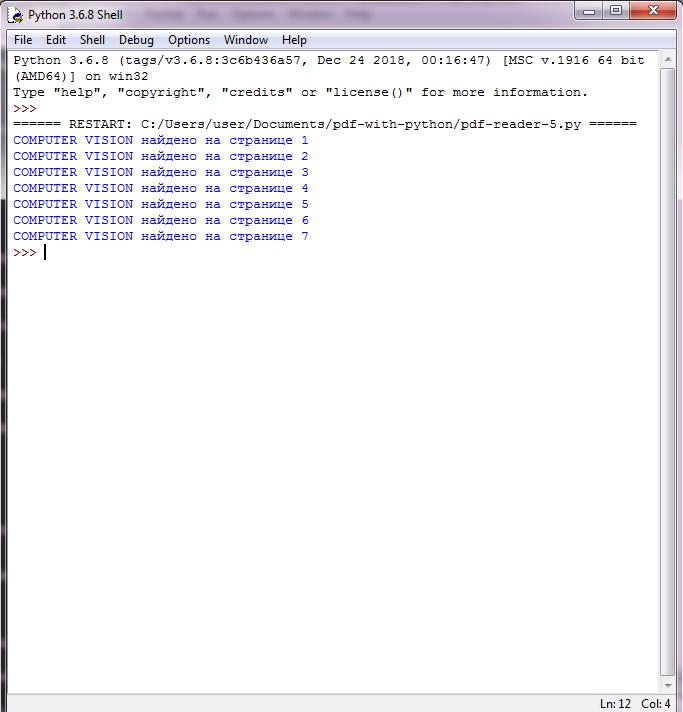 Результаты поиска COMPUTER VISION
Результаты поиска COMPUTER VISION
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты применения рассматриваются во второй части, посвященной добавлению водяного знака и картинок в PDF.
Продолжение цикла статей-конспектов на сайте
Источники вдохновения:
Работа с PDF-файлами в Python (часть I): чтение и разбор, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Чтение и запись файлов с использованием Pathlib
Следующие методы используются для выполнения основных операций, таких как чтение и запись файлов:
- : Файл открывается в текстовом режиме для чтения содержимого файла и его закрытия после чтения;
- : Используется для открытия файла в бинарном режиме, возвращения содержимого в бинарном форме и последующего закрытия файла;
- : Используется для открытия файла, записи туда текста и последующего закрытия;
- : Используется для записи бинарных данных в файл и закрытия файла по завершении процесса.
Давайте испытаем модуль Pathlib используя популярные файловые операции. Следующий пример используется для чтения содержимого файла:
Python
path = pathlib.Path.cwd() / ‘Pathlib.md’
path.read_text()
|
1 |
path=pathlib.Path.cwd()’Pathlib.md’ path.read_text() |
Метод для объекта используется для чтения содержимого файла. В примере ниже данные записываются в файл, в текстовом режиме:
Python
from pathlib import Path
p = Path(‘sample_text_file’)
p.write_text(‘Образец данных для записи в файл’)
|
1 |
frompathlib importPath p=Path(‘sample_text_file’) p.write_text(‘Образец данных для записи в файл’) |
Таким образом, в модуле Pathlib наличие пути в качестве объекта позволяет выполнять полезные действия над объектами для файловой системы, включая множество манипуляций с путями, таких как создание или удаление каталогов, поиск определенных файлов, перемещение файлов и так далее.
Заключение
Модуль Pathlib предоставляет огромное количество полезных функций, которые можно использовать для выполнения различных операций, связанных с путями. В качестве дополнительного преимущества библиотека согласовывается с операционной системой.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, \, , {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
os.path.split
Метод split разъединяет путь на кортеж, который содержит и файл и каталог. Взглянем на пример:
Python
import os
print( os.path.split(r’C:\Python27\Tools\pynche\ChipViewer.py’) )
# (‘C:\\Python27\\Tools\\pynche’, ‘ChipViewer.py’)
|
1 |
importos print(os.path.split(r’C:\Python27\Tools\pynche\ChipViewer.py’)) # (‘C:\\Python27\\Tools\\pynche’, ‘ChipViewer.py’) |
В данном примере показано, что происходит, когда мы указываем путь к файлу. Теперь взглянем на то, что происходит, если в конце пути нет названия файла:
Python
import os
print( os.path.split(r’C:\Python27\Tools\pynche’) )
# (‘C:\Python27\Tools’, ‘pynche’)
|
1 |
importos print(os.path.split(r’C:\Python27\Tools\pynche’)) # (‘C:\Python27\Tools’, ‘pynche’) |
Как видите, данная функция берет путь и разъединяет его таким образом, что подпапка стала вторым элементом кортежа с остальной частью пути в первом элементе. Напоследок, взглянем на бытовой случай использования split:
Python
import os
dirname, fname = os.path.split(r’C:\Python27\Tools\pynche\ChipViewer.py’)
print(dirname)
# C:\\Python27\\Tools\\pynche
print(fname)
# ChipViewer.py
|
1 |
importos dirname,fname=os.path.split(r’C:\Python27\Tools\pynche\ChipViewer.py’) print(dirname) # C:\\Python27\\Tools\\pynche print(fname) # ChipViewer.py |
В данном примере указано, как сделать множественное назначение. Когда вы разъединяете путь, он становится кортежем, состоящим из двух частей. После того, как мы опробовали две переменные с левой части, первый элемент кортежа назначен к первой переменной, а второй элемент к второй переменной соответственно.
Запись в файл
Функциональность внесения данных в файл не зависит от режима — добавление данных или перезаписывание файла. В выполнении этой операции также существует несколько подходов.
Самый простой и логичный — использование функции
Важно, что в качестве аргумента функции могут быть переданы только строки. Если необходимо записать другого рода информацию, то ее необходимо явно привести к строковому типу, используя методы для объектов или форматированные строки
Интенсив «Напишите первую модель машинного обучения за 3 дня»
7–9 декабря, Онлайн, Беcплатно
tproger.ru
События и курсы на tproger.ru
Есть возможность записать в файл большой объем данных, если он может быть представлен в виде списка строк.
Здесь есть еще один нюанс, связанный с тем, что функции и автоматически не ставят символ переноса строки, и это разработчику нужно контролировать самостоятельно.
Существует еще один, менее известный, способ, но, возможно, самый удобный из представленных. И как бы не было странно, он заключается в использовании функции . Сначала это утверждение может показаться странным, потому что общеизвестно, что с помощью нее происходит вывод в консоль. И это правда. Но если передать в необязательный аргумент объект типа , каким и является объект файла, с которым мы работаем, то поток вывода функции перенаправляется из консоли в файл.
Сила такого подхода заключается в том, что в можно передавать не обязательно строковые аргументы — при необходимости функция сама их преобразует к строковому типу.
На этом знакомство с базовой функциональностью работы с файлами можно закончить. Вместе с этим стоит сказать, что возможности языка Python им не ограничивается. Существует большое количество библиотек, которые позволяют работать с файлами определенных типов, а также допускают более тесное взаимодействие с файловой системой. И в совокупности они предоставляют разработчикам легкий и комфортный способ работы с файлами.
Способ 1
import os
import shutil
import glob
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
# получить список файлов в папке RandomFiles
files_to_group = []
for random_file in os.listdir('.'):
files_to_group.append(random_file)
# получить все расширения имен всех файлов
file_extensions = []
for our_file in files_to_group:
file_extensions.append(os.path.splitext(our_file))
print(set(file_extensions))
file_types = set(file_extensions)
for type in file_types:
new_directory = type.replace(".", " ")
os.mkdir(new_directory) # создать папку с именем данного расширения
for fname in glob.glob(f'*.{type}'):
shutil.move(fname, new_directory)
Для этого импортируем еще две библиотеки: shutil и glob. Первая поможет перемещать файлы, а вторая – находить и систематизировать. Но обо всем по порядку.
Для начала получим список всех файлов в директории.
Здесь мы предполагаем, что у нас нет ни малейшего понятия о том, какие именно файлы лежат в этой папке. Вместо того, чтобы вписывать все расширения вручную и использовать лестницу инструкций if или switch, мы желаем, чтобы программа сама просмотрела каталог и определила, на какие типы можно разделить его содержание. Что, если бы там были файлы с десятками расширений или логи? Вы бы стали описывать их вручную?
Получив список всех
файлов, мы заходим в еще один цикл, чтобы извлечь расширения названий.
Обратите внимание на разделение строки:
os.path.splitext(our_file)
Сейчас наша переменная выглядит как-нибудь так: . Когда разделим ее, получим следующее:
`('5', '.docx')`
Мы возьмем отсюда второй элемент по индексу , то есть . Ведь по индексу у нас располагается 5.
Таким образом, у нас имеется список всех файловых расширений в папке, в том числе повторяющихся. Чтобы оставить только уникальные элементы, преобразуем его во множество. К примеру, если бы этот список состоял исключительно из , повторяющегося снова и снова, то в set остался бы всего один элемент.
# создать множество и присвоить его переменной file_types = set(file_extensions)
Заметим, что в списке типов файлов каждое расширение содержит в начале. Если мы назовем так папки на UNIX-системе, то они будут скрытыми, что не входит в наши намерения.
Поэтому, итерируя
по нашему множеству, мы заменяем точку на пустую строку. И создаем папку с полученным
названием.
new_directory = type.replace(".", " ")
# наша директория теперь будет называться "docx"
Но чтобы переместить файлы, нам все еще нужно расширение .
for fname in glob.glob(f'*.{type}')
Этим попросту отбираем все файлы, оканчивающиеся расширением . Заметьте, что в нет пробелов.
Символ подстановки обозначает, что подходит любое имя, если оно заканчивается на . Поскольку мы уже включили точку в поиск, мы используем , что значит «все после первого символа». В нашем примере это .
Что дальше?
Перемещаем любые файлы с данным расширением в директорию с тем же названием.
shutil.move(fname, new_directory)
Таким образом, как только в цикле создана папка для первого попавшегося файла с данным расширением, все последующие файлы будут отправлены в нее же. Все будет сгруппировано без повторения каталогов.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку. Требуется время, чтобы понять, что к чему и какие проекты постоянно поддерживаются. Наше исследование позволило отобрать тех кандидатов, которые соответствуют современным требованиям:
- — библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
- — позиционируется как «быстрая и удобная библиотека чистого PDF» и реализована как оболочка для PDFMiner, и . Основная идея заключается в том, чтобы «надежно извлекать данные из наборов PDF‑файлов, используя как можно меньше кода».
- — расширение библиотеки , которое позволяет анализировать и конвертировать PDF‑документы. Не следует его путать с с таким же именем.
- — амбициозная промышленная библиотека, в основном ориентированная на оздание высококачественных PDF‑документов. Доступны как свободная версия с открытым исходным кодом, так и коммерческая, улучшенная, версия ReportLab PLUS.
- — чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF‑файлов в новых PDF‑файлах, созданных с помощью ReportLab.
В своём исследовании мы учитывали мнения Github-сообщества, а именно:
- Звёзды Github: общее количество звезд проекта, выставленных пользователям.
- Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
- Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
| Библиотека | Использование | Github | ReleasesGithub | Github |
|---|---|---|---|---|
| Чтение | 2 972 | 10 | 751 | |
| Чтение | 474 | 59 | 111 | |
| Чтение | 20 | 4 | ||
| Чтение | 85 | 69 | ||
| Чтение | 971 | 23 | 200 | |
| Чтение | 1 599 | 11 | 1 400 | |
| Чтение | 477 | 1 | 70 | |
| Чтение, Запись/Создание | 1 145 | 4 | 187 | |
| Запись/Создание | 31 | 48 | 22 | |
| Запись/Создание | 23 | 26 | 7 | |
| Запись/Создание | 457 | 7 | 174 |
Читать это руководство, не прорабатывая приведённые в нём примеры, бессмысленно. Поэтому, вооружимся и воспользуемся менеджером пакетов или pip3 для установки PyPDF2 и PyMuPDF. Наберём в командной строке (Windows):
pip3 install pypdf2 pip3 install pymupdf
Для того, что бы не запутаться создадим папочку для своего проекта. Как видите местом для неё выбрана папка «Документы» стандартной установки Windows.Вот так это выглядит в Windows
Папки и будем использовать для записи результатов работы своих программ, а в папке храним исходные PDF‑файлы, сами скрипты будем хранить в корне. Кстати, все примеры этой серии статей о работе с PDF‑файлами есть на , откуда их можно забрать и использовать в качестве «кирпича» для своих упражнений
Удаление строки
Чтобы в Python удалить ненужную строку из файла, следует воспользоваться сразу двумя режимами обработки файлов: чтение и запись. Для начала необходимо открыть test.txt для чтения, чтобы поместить информацию из него в отдельный массив lines. Далее потребуется удалить один из элементов последовательности при помощи оператора del, указав ему индекс нужной строки в квадратных скобках. Массив объектов, который получился в итоге, необходимо поместить в исходный текстовый файл, однако на этот раз открыть его надо в режиме записи.
with open(r"D:\test.txt", "r") as file:
lines = file.readlines()
del lines
with open(r"D:\test.txt", "w") as file:
file.writelines(lines)
Приведенный выше пример небольшой программы демонстрирует удаление строки из файла. В данном случае используются методы readlines и writelines, позволяющие считывать массив строк из документа и записывать его туда же, разделяя отдельные элементы списка.
Обратите внимание, что в приведенном примере удалится вторая строка, так как индексы списка считаются от нулевого элемента.
Таким образом, можно достаточно легко взаимодействовать с содержимым текстовых файлов, пользуясь языком программирования Python 3. Его встроенные функции позволяют записывать данные в документ и считывать их в удобном для пользователя виде. При помощи средств по расширенной работе с файлами, можно управлять ими на куда более продвинутом уровне.
Файлы в Python
В целом различают два типа файлов (и работы с ними):
- текстовые файлы со строками неопределенной длины;
- двоичные (бинарные) файлы (хранящие коды таких данных, как, например, рисунки, звуки, видеофильмы);
Этапы работы с файлом:
- открытие файла;
- режим чтения,
- режим записи,
- режим добавления данных.
работа с файлом;
закрытие файла.
В python открыть файл можно с помощью функции open с двумя параметрами:
- имя файла (путь к файлу);
- режим открытия файла:
- «r» – открыть на чтение,
- «w» – открыть на запись (если файл существует, его содержимое удаляется),
- «a» – открыть на добавление.
В коде это выглядит следующим образом:
Fin = open ( "input.txt" ) Fout = open ( "output.txt", "w" ) # работа с файлами Fout.close() Fin.close() |
Работа с текстовыми файлами в Питон
Чтение из файла происходит двумя способами:
- построчно с помощью метода readline:
файл input.txt:
1
2
3
str1 = Fin.readline() # str1 = 1 str2 = Fin.readline() # str2 = 2 |
метод read читает данные до конца файла:
файл input.txt:
1
2
3
str = Fin.read() ''' str = 1 2 3 ''' |
Для получения отдельных слов строки используется метод split, который по пробелам разбивает строку на составляющие компоненты:
str = Fin.readline().split() print(str) print(str1) |
Пример:
В файле записаны два числа. Необходимо суммировать их.
файл input.txt:
12 17
ответ:
27
Решение:
- способ:
Fin = open ( "D:/input.txt" ) str = Fin.readline().split() x, y = int(str), int(str1) print(x+y) |
способ:
... x, y = int(i) for i in s print(x+y) |
* Функция int преобразует строковое значение в числовое.
В python метод write служит для записи строки в файл:
Fout = open ( "D:/out.txt","w" )
Fout.write ("hello")
|
Запись в файл можно осуществлять, используя определенный
шаблон вывода. Например:
Fout.write ( "{:d} + {:d} = {:d}\n".format(x, y, x+y) )
|
В таком случае вместо шаблонов {:d} последовательно подставляются значения параметров метода format (сначала x, затем y, затем x+y).
Аналогом «паскалевского» eof (если конец файла) является обычный способ использования цикла while или с помощью добавления строк в список:
-
while True: str = Fin.readline() if not str: break
-
Fin = open ( "input.txt" ) lst = Fin.readlines() for str in lst: print ( str, end = "" ) Fin.close() - подходящий способ для Python:
for str in open ( "input.txt" ): print ( str, end = "" ) |
Задание Python 9_1:
Считать из файла input.txt 10 чисел (числа записаны через пробел). Затем записать их произведение в файл output.txt.
Рассмотрим пример работы с массивами.
Пример:
Считать из текстового файла числа и записать их в другой текстовый файл в отсортированном виде.
Решение:
- Поскольку в Python работа с массивом осуществляется с помощью структуры список, то количество элементов в массиве заранее определять не нужно.
- Считывание из файла чисел:
lst = while True: st = Fin.readline() if not st: break lst.append (int(st)) |
Сортировка.
Запись отсортированного массива (списка) в файл:
Fout = open ( "output.txt", "w" ) Fout.write (str(lst)) # функция str преобразует числовое значение в символьное Fout.close() |
Или другой вариант записи в файл:
for x in lst:
Fout.write (str(x)+"\n") # запись с каждой строки нового числа
|
Задание Python 9_2:
В файле записаны в целые числа. Найти максимальное и минимальное число и записать в другой файл.
Задание Python 9_3:
В файле записаны в столбик целые числа. Отсортировать их по возрастанию суммы цифр и записать в другой файл.
Рассмотрим на примере обработку строковых значений.
Пример:
В файл записаны сведения о сотрудниках некоторой фирмы в виде:
Иванов 45 бухгалтер
Необходимо записать в текстовый файл сведения о сотрудниках, возраст которых меньше 40.
Решение:
- Поскольку сведения записаны в определенном формате, т.е. вторым по счету словом всегда будет возраст, то будем использовать метод split, который разделит слова по пробелам. Под номером 1 в списке будет ити возраст:
st = Fin.readline() data = st.split() stAge = data1 intAge = int(stAge) |
Более короткая запись будет выглядеть так:
st = Fin.readline() intAge = int(st.split()1) |
Программа выглядит так:
while True: st = Fin.readline() if not s: break intAge = int (st.split()1) |
Но лучше в стиле Python:
for st in open ( "input.txt" ):
intAge = int (st.split()1)
if intAge < 5:
Fout.write (st)
|
Задание Python 9_4:
В файл записаны сведения о детях детского сада:
Иванов иван 5 лет
Необходимо записать в текстовый файл самого старшего и самого младшего.
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
Python
try:
file_handler = open(«test.txt»)
for line in file_handler:
print(line)
except IOError:
print(«An IOError has occurred!»)
finally:
file_handler.close()
|
1 |
try file_handler=open(«test.txt») forline infile_handler print(line) exceptIOError print(«An IOError has occurred!») finally file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране
Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
Python
try:
with open(«test.txt») as file_handler:
for line in file_handler:
print(line)
except IOError:
print(«An IOError has occurred!»)
|
1 |
try withopen(«test.txt»)asfile_handler forline infile_handler print(line) exceptIOError print(«An IOError has occurred!») |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
Python
This is test file
line 2
line 3
this line intentionally left lank
|
1 |
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
Python
handle = open(«test.txt»)
handle = open(r»C:\Users\mike\py101book\data\test.txt», «r»)
|
1 |
handle=open(«test.txt») handle=open(r»C:\Users\mike\py101book\data\test.txt»,»r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов
Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt
Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
Python
>>> print(«C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data\test.txt
|
1 |
>>>print(«C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data est.txt >>>print(r»C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
Python
handle = open(«test.txt», «r»)
data = handle.read()
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов. Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readline()# read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
Python
handle = open(«test.txt», «r»)
data = handle.readlines() # read ALL the lines!
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readlines()# read ALL the lines! print(data) handle.close() |
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Чтение и запись в бинарном режиме доступа
Что такое
бинарный режим доступа? Это когда данные из файла считываются один в один без
какой-либо обработки. Обычно это используется для сохранения и считывания
объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books =
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
Откроем файл на
запись в бинарном режиме:
file = open("out.bin", "wb")
Далее, для работы
с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него
метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")
и далее вызовем
метод load модуля pickle:
bs = pickle.load(file)
Все, теперь
переменная bs ссылается на
эквивалентный список:
print( bs )
Аналогичным
образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = "Евгений Онегин", "Пушкин А.С.", 200
book2 = "Муму", "Тургенев И.С.", 250
book3 = "Мастер и Маргарита", "Булгаков М.А.", 500
book4 = "Мертвые души", "Гоголь Н.В.", 190
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
А, затем,
считывание в том же порядке:
file = open("out.bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
Вот так в Python выполняется
запись и считывание данных из файла.