Yandex wordstat: подробная инструкция по использованию сервиса и операторов
Содержание:
- Зачем знать частотность запросов
- Что нужно делать.
- Кому и зачем следует знать принцип работы Яндекс.Вордстат?
- Сервис 2. Serpstat
- Для чего нужен Яндекс.Вордстат
- Скачать видео из Одноклассников по ссылке онлайн без программ
- Как узнать частотность ключевых запросов
- Рекомендации по подбору ключевых слов.
- Резюме
- Что можно делать с помощью SQL запросов
- Подбор «хвостов» с помощью QA-площадок
- Почему бизнесмены должны это знать
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Версии навигатора и системные требования для Андроид
- Метод для получения максимального охвата
- Зачем нужен Вордстат?
- Работа с Парсером Wordstat при сезонном спросе
Зачем знать частотность запросов
Частотность запросов собирают для прогнозирования трафика. Парсер Wordstat показывает, сколько раз за месяц пользователи вводили в поиске определенную фразу. Эти данные позволяют примерно рассчитать, сколько сайт получит переходов, если займет N-ую позицию в поиске.
Как это работает на практике:
1. Собираете список ключевых фраз. Быстро подобрать ключевики можно с помощью инструмента медиапланирования.
2. Определяете частотность запросов для фразы. Например, «купить Samsung Galaxy в Москве» — 11757 показов в месяц.
3. Узнаете значения CTR в зависимости от позиции в поиске.
Сделать это можно двумя способами:
- Найти данные о распределении CTR в открытых источниках.
- Посмотреть в отчете Яндекс.Вебмастера. Для этого в левом меню выберите «Поисковые запросы» — «Все запросы и группы». Данные отображаются в столбце «CTR на позициях, %».
Последний способ доступен в том случае, если ваш сайт добавлен в Яндекс.Вебмастер и работает хотя бы несколько месяцев.
4. Составляете прогноз трафика для ТОП-10. Для этого умножаете частотность на CTR и делите на 100%.
Например, если CTR на 2-3 позиции составляет 25%, то прогнозный трафик при достижении этой позиции равен: 11757*25/100 = 2939.
Вторая причина анализа частотностей — отсеивание «мусорных» фраз. Это фразы, частотность которых стремится к нулю, и их нет смысла включать на существующие страницы или создавать под них новые страницы.
Но не все ключевые фразы с низкой частотностью являются «мусорными»
Здесь важно учитывать тематику сайта. Если она узкая, то рекомендуется оставлять фразы даже с частотностью 1
Например, по запросу «купить фотоколориметр КФК-3-01» можно получить 1 показ в месяц. Но сайт специализируется на продаже лабораторного оборудования, т.е. относится к сайтам узкой тематики. В таких ситуациях каждый посетитель имеет ценность.
Для магазинов масс-маркета можно отсеивать запросы с частотностью ниже 5. А для информационных сайтов частотность 30-50 вполне может быть нижним пределом. Главное, не переусердствуйте с удалением лишних фраз, иначе есть риск потерять трафик по низкочастотным запросам, который порой составляет до 70-80 % от общего трафика.
Что нужно делать.
Поэтому при сборе семантики, при сборе ключевых слов для Директа, нужно отталкиваться от логики.
Нужно использовать горячие запросы, их тестировать, использовать запросы с указанием точного наименования товара, именно те запросы, которые характеризуют намерения покупатели приобрести или заказать какой-то товар.
Во вторую группу запросов можно определять некие информационные запросы, но здесь уже нужно тестировать и смотреть, будут ли по ним продажи.
Но первую ставку нужно делать именно на горячие запросы. А не раздувать свою рекламную кампанию, чтобы она была непомерно большой.
Кому и зачем следует знать принцип работы Яндекс.Вордстат?
Онлайн-сервис Вордстат – незаменимый помощник для SEO-оптимизаторов и специалистов по контекстной рекламе, продвигающих товары и услуги в Яндекс.Директ.
Работая с Яндекс.Вордстат, вы получите:
- список популярных ключевых запросов для создания рекламной кампании и продвижения веб-ресурса в поисковой выдаче;
- прогноз трафика, анализ частотности показов ключевых слов, соответственно, уровень спроса на тот или иной товар/услугу;
- тренды – запросы пользователей, которые только набирают популярность;
- полезные идеи и помощь при создании новых страниц веб-сайта.
Нужно ли изучать Яндекс.Вордстат владельцам бизнеса, нанимающим вышеперечисленных специалистов? Однозначно – да! Хотя бы поверхностное знание работы сервиса даёт возможность понимать, как и с помощью чего привлекаются новые клиенты. Таким образом, удаётся контролировать работу исполнителей.
Особенно важно тесное сотрудничество между заказчиком и исполнителем при продвижении бизнеса, предлагающего узкоспециализированные товары или услуги. В этом случае, знание и использование отраслевых терминов – верный путь к привлечению постоянных и крупных клиентов
Сервис 2. Serpstat
Serpstat – анализирует ключевые фразы, помогая в составлении семантического ядра сайта.
- Собирает эффективные ключи, по которым конкурирующие сайты занимают места в ТОПе.
- Сравнивает ключевики по количеству запросов, ценам за клик, степени конкуренции и количеству результатов
- Определяет релевантность страниц сайта под конкретные поисковые запросы
- Предоставляет данные по популярности кл. слов, показывает изменение интересов пользователей в течение года, позволяет учитывать сезонность и тренды
- Показывает полный список поисковой выдачи по кл. слову и объём потенциального трафика для каждой страницы сайта
- Показывает ваших конкурентов в органической выдаче
- Определяет показатель видимости вашего сайта и сайтов-конкурентов
- Показывает позиции конкурентов в результатах выдачи в пределах ТОП 100 и отслеживает изменение позиций
Цены
Сервис предлагает 4 тарифа:
- Plan A – 19,00 $ в месяц.
- Plan B – 69,00 $ в месяц.
- Plan C – 149,00 $ в месяц.
- Plan D – 299,00 $ в месяц.
Для чего нужен Яндекс.Вордстат
Яндекс.Вордстат — бесплатный сервис для получения статистики поисковых запросов в Яндексе. С помощью сервиса можно посмотреть, сколько раз пользователи искали определенный поисковой запрос на протяжении месяца. Но это далеко не всё.
Какие данные выдает Вордстат
1. Статистика по частотности:
- указанного запроса;
- запросов, которые содержат указанную фразу или слово.
2. Похожие запросы для расширения семантики.
3. Данные по частотности с разбивкой по регионам и городам.
4. Данные по показам с разбивкой по типу устройств (десктопы, смартфоны, планшеты).
5. Сезонные колебания спроса по выбранной фразе (динамика популярности фразы за прошедшие два года в разрезе месяца или недели с разбивкой по типу устройств).
Скачать видео из Одноклассников по ссылке онлайн без программ
- Не нужно проводить установку приложений.
- Он полностью безопасен.
- Исключена вероятность заражения вирусами ПК.
- Вся процедура занимает минимум времени.
- Вы сможете получить быстрый доступ к видео.
- Зайти в ОК.
- Перейти в раздел видео.
- Найти нужный ролик.
- Открыть его в окне.
- Нажать строчку с адресом.
- Скопировать содержимое.
- Проследовать на сайт telechargerunevideo.com/en.
- Вставить ссылку в строку.
- Нажать на кнопку рядом с ней.
- Вы получите доступ к видео.
- Сможете выбрать формат и начать скачивание.
- Видео отправляется в папку, используемую для загрузок.
В дальнейшем вы сможете свободно распоряжаться файлом. Весь процесс занимает у пользователей минимум времени, обычно не возникает дополнительных трудностей.
Как узнать частотность ключевых запросов
Если у вас уже есть определенные наметки по будущей тематике сайта, то достаточно набросать предварительный список наиболее популярных в этой теме запросов и «пробить» их частотность через сервис – wordstat.yandex.ru.
Например, пришла в голову идея сделать сайт по разведению оленей, можно посмотреть, сколько людей ищут «как разводить оленей».
Популярность запроса в поисковой системе Яндекс будет выражена конкретными цифрами, а дальше вы уже сами оценивайте, как это впишется в ваш бизнес план.
Видим, что тема про оленей не особо востребована, может быть, стоит для сайта подобрать какие-то более популярные запросы и вкладываться в них.
Максимум, что мы можем извлечь из этого сервиса – это посмотреть популярность сложных ключевых запросов (состоящих из 2 и более слов) с обязательным вхождением одного из них.
Например, ищем, что чаще всего хотят купить люди. Их запросы должны выглядеть так – «купить …» (вместо троеточия слово). В поле вордстата вводим «купить» и в списке предложенных вариантов мы увидим все самые популярные запросы купить в Яндексе. Подборка ключей для магазина авто шин может начинаться с общего запроса «купить шины»:
По списку уже видно чего и сколько ищут. Из общего запроса можно выделить множество групп более узкой специализации. Каждую из этих групп можно потом рассмотреть индивидуально по той же схеме и вычленить запросы из 4-5 слов. Для интернет магазина все закончится на самых узких запросах – карточках товаров.
Аналогично можно искать слова «смотреть», «скачать» и т.д. Если нужная вам тематика имеет подобные объединяющие слова, то вам повезло. Сложнее, когда все запросы в теме не похожи друг на друга. Как их выудить я расскажу дальше.
Здесь подробнее о том, как работать с Яндекс Вордстат.
Рекомендации по подбору ключевых слов.
Какой общий совет по настройке Директа в плане ключевых слов – нужно ориентироваться на горячие запросы, потому что нужно понимать, что за каждым запросом стоит потребность определенного человека. этот человек – потенциальный покупатель. Он использует поисковую систему, это может быть Яндекс или Гугл с одной целью – найти решение возникшей у него проблемы.
Здесь мы можем вспомнить лестницу Ханта, каждый покупатель находится на определенном уровне этой лестницы. Нас интересует только те, которые уже точно знают, чего они хотят. Как правило, они используют идентифицирующие их намерения слова. Такие как купить, заказать, интернет магазин, наложенным платежом.
Во вторую очередь эти люди используют конкретные наименования товаров, более точные модели называются, скорее всего человек собирает информацию по этой модели, и хочет ее купить. Я бы определял какие запросы во вторую группу.
Когда мы используем информационные запросы – это характеризует положение человека на лестнице Ханта. То есть информационный – это означает, что он либо уже купил товар и добирает не хватающую ему информацию: как там пользоваться или какие-то нюансы решить. Либо он еще точно не сформировал свою потребность приобрести этот товар, и просто собирает информацию. Такой человек, как может купить, так может и не купить.
И как правило, в процентном соотношении большая часть тех, кто приходит по информационным запросам, они ничего не покупают.
Все равно эту продающую базу формируют горячие запросы, потому что при настройке Директе, когда очень много объявлений, сначала идет запуск, потом идет тестирование, после того, как просматриваются аналитические данные, в Яндекс Метрике, например.
Если смотреть данные по целям, то видно, что лишь меньшая часть запросов реально приносят продажи, они реально окупаются.
Общий совет еще какой – избавиться от этих стереотипов, типа там, чем больше запросов, тем больше продаж – это совершенно не правда. Избавиться от стереотипа, что НЧ-запросы – они наиболее дешевые. Это не правда. То, что они низкочастотные не говорит о их дешевизне.
Избавиться от того, что чем больше у вас будет низкочастотных запросов, тем выше у вас будет ctr. Это тоже не совсем верно. Если у вас будут 0 в месяц по некоторым запросам, у вас ctr общая будет падать.
И использование искусственной семантики – лично я бы ее не использовал. То есть я видел, один человек снимал видео курсы и показывал, как он собирал то ли 400 запросов искусственно сформированных, при этом используя базы Пастухова. Там статистика запросов за 7 лет, по-моему, если там ввести ваш запрос, можно сделать выгрузку, и там он выгрузит запросто несколько тысяч слов .
Это такие слова длинные, многосоставные, 7-8 слов может быть в этом запросе. По ним, конечно, могут быть клики, раз в год, не знаю. Получается, когда у вас много таких запросов, вы повышаете нагрузку на себя, за всем же этим нужно следить.
К примеру, если в кампании тысяча объявлений – это просто сложно все оптимизировать и сложно собирать какие-то данные, потому что это очень усложняет аналитику.
Резюме
В следующей статье мы рассмотрим вопрос распределения ключевых слов по страницам сайта и составления структуры сайта на основе собранной семантики.
Вступайте в Клуб SEO-специалистов, где будут анонсироваться новые статьи по SEO-курсу.
Рекомендуем
Как составить текст ссылки?
Один из самых важных вопросов в продвижении сайта – какие тексты ссылок использовать? На этот счет существует множество мнений, я изложу только …
Как провести технический аудит сайта?
Технический аудит сайта выявляет ошибки в работе веб-ресурса, которые могут вызвать проблемы в поисковых системах. Например, усложнить индексацию …
Что можно делать с помощью SQL запросов
Подбор «хвостов» с помощью QA-площадок
Площадки вопросов-ответов — это хороший способ найти «живую» семантику. В России самая популярная — Ответы Mail.ru. Также есть тематические QA-площадки (например, для айтишников — Toster). Среди западных QA-площадок самая известная — Quora.
Итак, как с ними работать. Заходим на выбранный QA-сайт и вводим интересующий запрос. Получаем похожие вопросы по теме. По сути, это и есть НЧ семантика.
Копировать вопросы вручную — не наш путь. Выделяем любой вопрос, кликаем по нему правой кнопкой мыши и контекстном меню выбираем «Scrape similar…» (используем расширение Scraper, о котором рассказывали в предыдущем пункте).
Парсер собирает все вопросы на странице. Копируем и забираем в «эксельку».
Если вы используете другой Xpath-парсер, кликните по интересующему объекту правой кнопкой мыши и в контекстном меню выберите «Просмотреть код». Кликните по подсвеченному участку кода правой кнопкой мыши и в пункте «Copy» выберите «Copy Xpath».
Полученный код вставьте в парсер и загрузите список URL для проверки. Например, это можно сделать в Screaming Frog SEO Spider. Как? Читайте здесь.
Бесплатная альтернатива — Google Таблицы. С помощью функции IMPORTXML и Xpath-запроса вы без проблем выгрузите данные со страницы.
Синтаксис формулы такой:
Достаточно указать URL, сослаться на этот URL в формуле, и Google автоматически спарсит все элементы страницы, которые соответствуют Xpath-запросу.
Больше о полезных формулах Google Таблиц для SEO читайте в нашей .
Помимо QA-площадок можно найти НЧ с помощью сервиса AnswerThePublic. Он собирает вопросы с вхождением ключа, «хвосты» с предлогами, сравнения, связанные запросы. Раньше сервис был англоязычным, и приходилось переводить полученные ключи и вопросы. Но недавно появилась поддержка русского языка.
Сервис работает так: вводите ключевое слово, и получаете «вал» ключей с визуализацией связей:
Для выгрузки ключевых слов нажмите «Download CSV».
В загруженной таблице будут все собранные слова:
Почему бизнесмены должны это знать
Некоторые руководители компаний ошибочно считают, что в Wordstat должны разбираться только SEO-специалисты, аналитики и таргетологи. Нужно помнить, что услуги сторонних агентств или штатных маркетологов оплачивает бизнес. Платить и не понимать за что именно – это вариант для состоятельных людей, которым больше важен процесс, а не его результат. Мы выделили основные причины, ради которых бизнесменам все-таки стоит разобраться с тем, что такое «Яндекс.Статистика».
Объективная оценка исполнителей
Сложно представить себе человека, который бы просто перевел деньги строительной компании и сказал: «Просто постройте мне хороший дом. Вы же специалисты и все понимаете, а я не хочу вникать в детали». А на рынке интернет-маркетинга подобные ситуации случаются регулярно. Если заказчик не понимает, что он хочет получить, то подрядчикам можно сильно и не стараться. При этом простая статистика запросов по словам может показать, какой контент действительно нужно добавить на сайт и какие фразы включить в семантическое ядро. К примеру, если тематика бизнеса охватывает тысячи популярных ключевых запросов, а маркетологи основывают стратегию на паре десятков простых в продвижении фраз, то бизнес просто теряет свою прибыль и рекламный бюджет.
Работа в узких тематических нишах
Программа анализа запросов «Яндекс.Вордстат» – это прежде всего инструмент, а не панацея. Нанятый маркетолог может просто не разбираться в тонкостях ниши клиентского бизнеса. В некоторых отраслях могут насчитывать сотни специфических терминов. Недостаточное погружение специалиста в тему – это совсем не повод терять поисковый и рекламный трафик. Приведем простой пример. Скорее всего, у вас есть или был велосипед. Но знаете ли вы, что такое башинг, баттинг, брейкбоссы, грипсы, дропаут или хардтейл? Если выполнить подбор слов по базовым ключевикам в «Яндекс.Вордстате», то сервис не покажет запросов со специфическими терминами. С другой стороны, аудитория, которая ищет «хардтейл с титановыми боссами для вибрейков», является для бизнеса очень перспективной, так как это люди, которые уже точно знают, что им нужно. С помощью статистики «Яндекс.Вордстата» можно найти узкие ниши с минимальной конкуренцией и очень конверсионным трафиком.
Продвижение по артикулам, синонимам и аббревиатурам
Если в стратегию продвижения включены конкретные и не всегда однозначные поисковые запросы, то успешно реализовать ее невозможно без деятельного участия владельца бизнеса в процессе составления семантической базы.
В противном случае возникает высокая вероятность:
- значительного расходования средств на запросы с низкой доходностью;
- некорректного определения интересов и потребностей целевой аудитории;
- продвижения в нерелевантной нише.
К примеру, на строительном рынке представлена популярная краска «ВДС-10». Если продвигать страницы и заказывать рекламу только по названию, то с высокой долей вероятности сайт получит трафик из пользователей, которым нужен сервер VDS. Очевидно, что такие переходы не будут отличаться приятной конверсией.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Версии навигатора и системные требования для Андроид
Метод для получения максимального охвата
Этап 1: соберите общие фразы, которые описывают ваш продукт
Ответьте на вопрос, как его называет ЦА. Придумайте все возможные формулировки, написания (в том числе русские для зарубежных брендов) и синонимы.
Можно взять их из описания сегментов целевой аудитории. В нашем примере — семантика для курсов английского языка, сегмент «Карьеристы».
Примерные запросы для этого типа ЦА:
- «Деловой английский курсы»;
- «Бизнес английский»;
- «Карьера в зарубежной фирме»;
- «Английский для работы»;
- «Деловой английский по скайпу»;
- «Курсы английского с сертификатом»;
- «Английский интенсивный курс».
Постройте таблицу в любом формате, чтобы фиксировать идеи. Занесите то, что есть на данный момент:

Это удобный формат отчета: всё сгруппировано по темам, брендам, категориям, проще оценивать общую частотность и в дальнейшем — размер низкочастотного хвоста.
Столбец «Семантика» — это количество уникальных фраз с ненулевой частотностью для этой маски. Его мы заполняем далее — на этапе парсинга СЯ. Сейчас только выписываем частотность из Яндекс Wordstat.
Столбец «Раздел» пригодится, если у вас много товаров, брендов, категорий.
Этап 2: пробейте фразы в Wordstat
Используйте только широкое соответствие, чтобы получить по максимуму вложенные запросы из каждого базиса.
Сервис выдает количество показов рекламных блоков Яндекса. Чем уже запрос, тем меньше предполагаемое количество запросов и трафика на сайт, а следовательно — охвата ЦА.
Не забудьте настроить регион, если у вас локальный бизнес.
Фразы с очень низкими показателями лучше заменить на более емкие, так как ваша задача — получить маски, которые потенциально дают большое количество расширений при дальнейшем парсинге.
При этом исключайте варианты с нулевой частотностью:
Можно их также уточнить, чтобы получить больший прогнозируемый охват
Но учитывайте, что при этом в выдаче могут появиться нецелевые запросы, например:
Желательно сразу вносить их в минус-файл либо исключить при поиске:
Важно! Оценивайте результаты выдачи сразу, чтобы в дальнейшем избежать лишней работы. Если в выборке много лишнего, не стоит брать этот базис.
Например, запрос «Английский для работы» дает не те результаты, которые нужны для СЯ
Мы подразумевали под работой карьеру, но не как школьное задание.
В нашем случае всё, что связано со школой — «контрольная работа», «домашняя работа», «по-английски», «рабочая тетрадь» и т.д. — это минус-слова.
Пробуем уточнить формулировку. Совсем другая ситуация по фразе «Английский для работы за рубежом», но выдача маленькая.
Принцип №1: для полноценного СЯ подбирайте такие маски, чтобы «зацепить» больше расширений (охвата) и меньше «мусора».
По мере парсинга масок в Wordstat заполняйте таблицу. У нас получаются такие данные:
Результаты довольно скромные, если пользоваться только выдачей Wordstat. За счет чего их можно расширить? Идем дальше.
Этап 3: посмотрите похожие запросы в Яндекс Wordstat
Принцип №2: используйте ключевые фразы в правом столбце как идеи, а не просто копируйте. Выделяйте из них полезные составляющие, расширяйте их как угодно, убирайте лишние слова.
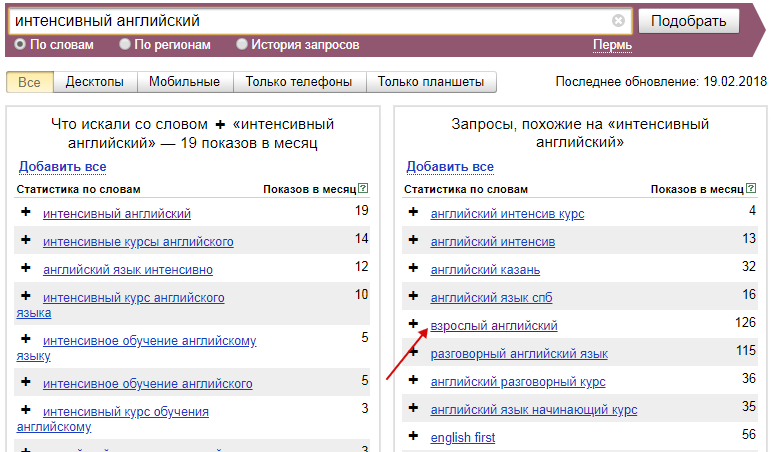
Параллельно проверяйте каждую идею на содержание в поисковиках, чтобы представлять, какие запросы по нему вводят:

И отсеивайте то, что не попадает в тему.
Этап 4: изучите источники семантики
Принцип тот же — придумывайте маски из того, что увидите. Например, загляните в:
Поисковые подсказки Яндекс и Google:
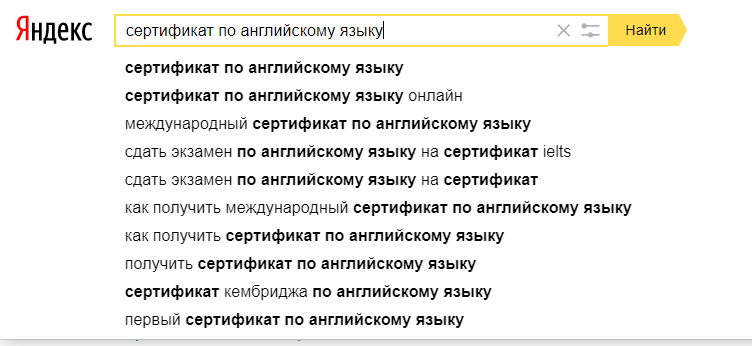
Похожие запросы в SERP:

Статистику запросов Mail.ru

А также сервисы синонимов, форумы, Alt-теги к картинкам в поисковой выдаче, Планировщик ключевых слов Google и т.д.
Полезно черпать идеи с сайтов конкурентов.
Отдельно пара слов о сервисе SpyWords. Это не буквальное руководство. База запросов, по которой раз в месяц снимается поисковая выдача и реальные запросы — это разные вещи. Копировать их бессмысленно, а поискать идеи для новых масок стоит.
Рекомендация та же: проверяйте результаты в поисковой выдаче. Плюс пробивайте на частотность в Яндекс Wordstat.
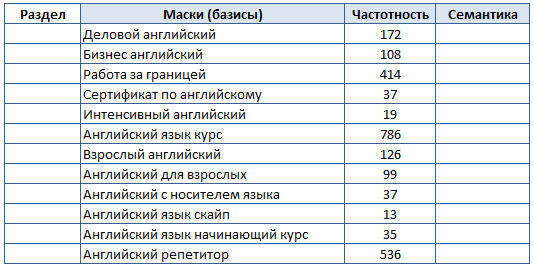
Заносите в таблицу те, где частотность выше нуля. Вот некоторые маски, которые мы получили из похожих запросов и поисковых подсказок:
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Работа с Парсером Wordstat при сезонном спросе
Wordstat выдает статистику за последние 30 дней. Поэтому если по запросу наблюдается сезонный спрос, то полученные данные могут быть завышенными или заниженными. Если вы видите в отчете парсера нули и подозреваете, что со статистикой что-то не так, перейдите в Wordstat и посмотрите «Историю запросов». Ярко выраженная сезонность будет видна на графике:
Уточнение частотности слов — один из этапов работы с семантикой. В Click.ru вы найдете полный перечень инструментов для работы с семантическим ядром. Например, для очистки семантики от дублей используйте нормализатор слов, для разделения семантического ядра на кластеры — кластеризатор запросов, а для его расширения воспользуйтесь сбором поисковых подсказок и сбором фраз-ассоциаций.