Основные модели данных: иерархическая, сетевая, реляционная
Содержание:
- Табличные базы данных
- Объектно-ориентированные субд
- Как работают базы данных.
- Отзывы и комментарии о сайте: cashbox.ru
- Принцип построения иерархической модели
- Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
- Тип поля
- Пример табличной базы данных
- Как хранится информация в БД
- Как настроить роутер ASUS RT-N11P?
- Состав частей реляционной модели данных
- Плоская модель
- Примеры типичных операторов поиска данных
- Обобщенное описание структуры
- Структурная часть иерархической модели
- В чём преимущества
- Виды баз данных
- MEMORY (HEAP)
Табличные базы данных
База данных, хранящая данные о группе объектов с одинаковыми свойствами, представляется в виде двумерной таблицы, где каждая ее строка последовательно размещает значения свойств одного из объектов; а каждое значение свойства находится в своем столбце, названном по имени свойства.
Столбцы подобной таблицы называются полями, причем каждое поле имеет свое имя (имя соответствующего свойства) и тип данных, который представляет значения этого свойства.
Поле базы данных является столбцом таблицы, содержащим значения определенного свойства.
Определение 2
Строки таблицы – это записи об объекте, которые разбиты на поля столбцами таблицы, в результате каждая запись представлена набором значений, находящихся в полях.
Запись базы данных представляет собой строку таблицы, содержащую набор значений свойств, размещенных в полях базы данных.
Каждая таблица, как правило, содержит одно ключевое поле, содержимое которого является уникальным для каждой записи данной таблицы. С помощью ключевого поля однозначно идентифицируются записи в таблице.
Замечание 2
Таким образом, ключевое поле является полем, значения которого однозначно определяют записи в таблице.
Ключевое поле, как правило, имеет тип данных счетчик. Однако в некоторых случаях удобнее, чтобы ключевое поле таблицы имело другой тип (например, числовой — инвентарный номер или код объекта).
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Отзывы и комментарии о сайте: cashbox.ru
Принцип построения иерархической модели
Иерархическая модель данных строится по следующему принципу:
- для каждого узла древовидной структуры ставится в соответствие некий сегмент;
- под сегментом понимаются поля данных с присвоенным каждому полю именем и выстроенные в один линейный кортеж;
- еще одно соответствие: один входной и несколько выходных сегментов для каждого исходного поля;
- для каждого структурного элемента существует одно и только одно место в системе иерархии;
- древовидная структура начинается с корневого элемента;
- у каждого подчиненного узла только один предок, но у каждого исходного может быть несколько потомков.
Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
Это в равной мере относится и к программам, и к драйверам, которые могут не соответствовать требованиям Windows 10 и работать некорректно. Обратитесь к сайту производителя вашего ПО или драйвером и скачайте новую версию, возможно она уже имеет поддержку Windows 10. В любом случае старую версию программы или драйвера нужно удалить и тогда ошибки не будет.
Тип поля
Тип поля определяется по типу данных, содержащихся в нем. В полях могут содержаться данные следующих типов:
- Счетчик, в нем содержится последовательность целых чисел, задаваемых автоматически при вводе записей. Пользователь данные числа не может изменить;
- Текстовый, в нем содержатся символы различных типов;
- Числовой, в нем содержатся числа различных типов;
- Дата/Время используется для содержания даты или времени;
- Картинка, используется для хранения изображения;
- Логический, имеет значения Истина (Да) или Ложь (Нет).
Для каждого типа характерен свой набор свойств. Наиболее важными из которых являются:
- размер поля используется для определения максимальной длины текстового или числового поля;
- формат поля используется для установления формата данных;
- обязательное поле используется для указания на то, что это поле обязательно нужно заполнить.
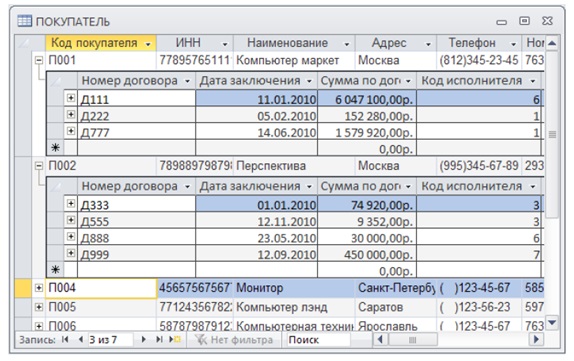
Пример табличной базы данных
Рассмотрим базу данных «Компьютер» (рис.3), которая представляет собой перечень объектов (компьютеры), каждый из которых имеет свое имя (название). В качестве характеристик (свойств) будут выступать тип процессора и объем оперативной памяти.
Столбцы этой таблицы представляют поля, каждое из которых имеет свое имя (название соответствующего свойства) и тип данных, которые отражают значения этого свойства. Тип полей Название и Тип процессора — текстовый, а тип поля Оперативная память — числовой. При этом каждое поле имеет определенный набор свойств (размер, формат и др.). Так, для поля Оперативная память задается формат данных «целое число».
Определение 3
Полем базы данных является столбец таблицы, который включает в себя значения определенного свойства.
Строки таблицы представляют записи об объекте, которые разбиты столбцами таблицы на поля. Запись базы данных представляет собой строку таблицы, содержащую набор значений различных свойств объекта.
Замечание 3
Каждая таблица должна иметь хотя бы 1 ключевое поле, содержимое которого является уникальным для любой записи в данной таблице. Значениями ключевого поля однозначно определяются записи в таблице.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Как настроить роутер ASUS RT-N11P?
После всего этого можно смело открыть браузер и ввести адрес http://192.168.1.1, по которому находится вход в настройки роутера Асус. Здесь нужно отметить, что в зависимости от модификации, этот адрес может отличаться, например будет 192.168.0.1, 192.168.0.10 или 192.168.1.10. Чтобы этот момент уточнить, загляните в ту же самую этикетку, которая находится на нижней крышке маршрутизатора — там имеется вся необходимая информация для подключения.
После входа в панель управления мы попадаем в мастер быстрой настройки, что очень удобно для пошаговой установки подключения Асус к интернету, особенно для новичков. В первом окне просто жмем на «Перейти»
Далее нам предлагается сразу же сменить пароль на роутер, чтобы обеспечить безопасность входа в его настройки — задаем свой пароль.
Далее начнется процесс автоматического определения типа вашего подключения к интернету. Поскольку у меня в данный момент используется «Динамический IP», никаких дополнительных проверок и авторизаций проходить не нужно. Если же у вас другой тип, то его можно задать позже уже в полном меню настроек Асус.
На последнем шаге — установка имени для беспроводной сети и пароля для подключения (тут он называется «сетевой ключ»). В данной модели wifi работает только на частоте 2.4 ГГц. В некоторых других, у которых есть поддержка 5 ГГц, нужно было бы еще настроить и вторую сеть.
В заключительном окне отобразятся все только что заданные параметры нашей сети.
При этом наш wifi уже появился в списке беспроводных подключений
Для того, чтобы зайти обратно в маршрутизатор, теперь уже потребуется ввести логин и пароль, которые мы задали на первом шаге.
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц
Важно что реляционная база данных, структурно может представляться только в виде отношений
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Плоская модель
Модель плоского файла
Модель плоской (или таблица) состоит из одного двумерного массива данных элементов, где предполагаются все члены данного столбца , чтобы быть аналогичные ценности, и все члены ряда предполагаются связанными друг с другом. Например, столбцы для имени и пароля, которые могут использоваться как часть базы данных безопасности системы. Каждая строка будет иметь конкретный пароль, связанный с отдельным пользователем. Столбцы таблицы часто имеют связанный с ними тип, определяющий их как символьные данные, информацию о дате или времени, целые числа или числа с плавающей запятой. Этот табличный формат является предшественником реляционной модели.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Виды баз данных
Как известно, различают четыре вида посторения БД:
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.