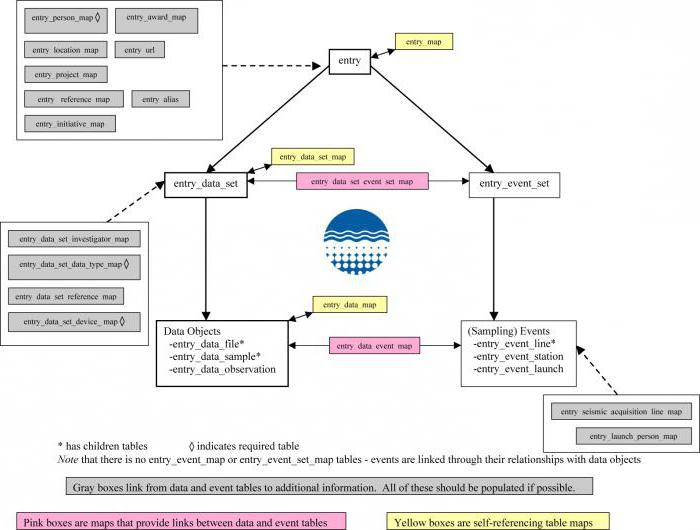
Реляционная база данных. проектирование реляционных баз данных
Содержание:
- Достоинства и недостатки реляционной модели данных
- Ключи
- Как ускорить работу компьютера (ноутбука) Windows 7
- Фундаментальные модели
- Как хранится информация в БД
- Устройство реляционной базы данных – таблицы, строки, столбцы
- Структура данных в реляционной модели данных
- Ключи в БД
- В чём преимущества
- Как узнать настоящую реляционную БД
- Что такое нереляционная база данных
- Концептуальная модель базы данных
- Реляционные операции
- Калькулятор расчета пенсии
- Жесткие диски цены
- Доля рынка
- 5 последних уроков рубрики «Разное»
- Особенности, структура и термины, связанные с реляционной моделью
- Реляционная модель
- Базовые и производные отношения
- Терминология
- Структура реляционной таблицы
- История разработки
- Структурная таблица
- Итоги
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
Ключи
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций.
Часть этой обработки включает постоянную возможность выбрать или изменить одну и только одну строку в таблице. Таким образом, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другие, более естественные ключи также могут быть идентифицированы и определены как альтернативные ключи (AK). Часто для формирования AK требуется несколько столбцов (это одна из причин, по которой один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Дополнительная технология может применяться для обеспечения уникального идентификатора во всем мире, глобального уникального идентификатора , когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда ПК переходит в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять отношения « один к одному» или « один ко многим» . Большинство проектов реляционных баз данных разрешают отношения « многие ко многим» путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей — отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы — вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе множества других типов столбцов.
Отношения
Отношения — это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Как ускорить работу компьютера (ноутбука) Windows 7
Фундаментальные модели
Возвращаясь к возникновению баз данных, стоит сказать, что этот процесс был достаточно сложным, он берет свое начало вместе с развитием программируемого оборудования обработки информации. Поэтому неудивительно, что количество их моделей на данный момент достигает более 50, но основными из них считаются иерархическая, реляционная и сетевая, которые и до сих пор широко применяются на практике. Что же они собой представляют?
Иерархическая база данных имеет древовидную структуру и составляется из данных разных уровней, между которыми существуют связи. Сетевая модель БД представляет собой более сложный шаблон. Ее структура напоминает иерархическую, а схема расширенная и усовершенствованная. Разница между ними в том, что потомственные данные иерархической модели могут иметь связь только с одним предком, а у сетевой их может быть несколько. Структура реляционной базы данных гораздо сложнее. Поэтому ее следует разобрать более подробно.

Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Устройство реляционной базы данных – таблицы, строки, столбцы
Множество это набор уникальных значений, которые закрыты от других множеств (ограничение), не упорядочены (до любого значения можно добраться, не затрагивая другие значения) и уникальны.
Атрибут множества, это название столбца в таблице БД. Математически, атрибут это множество, названий столбцов. Каждое название столбца уникально и неупорядочено. То есть, мы можем «добраться» до уникального названия столбца не затрагивая другие столбцы.
Очень важна уникальность атрибутов (названий столбцов) в рамках базы данных. Достигается уникальность столбцов, добавлением в его названия имя таблицы данных.
О неупорядоченности атрибутов
Математически, множество атрибутов: B.4, B.89, B.55, B.3, B.99, точно такое же, как множество: B.89, B.55, B.4, B.99, B.3. Но на практике, мы не можем вызывать столбцы по названию в произвольном порядке. Для упорядочивания вызова и нужен структурный язык. Для реляционных баз данных структурный язык это язык: SQL. В нем упорядоченный вызов столбцов поатрибутам выглядит так:
SELECT B.4, B.89, B.55, B.3, B.99 FROM B
Или
SELECT B.89, B.55, B.4, B.99, B.3 FROM B
Структура данных в реляционной модели данных
Реляционная модель данных предусматривает структуру данных, обязательными объектами
которой являются:
отношение;
атрибут;
домен;
кортеж;
степень;
кардинальность;
первичный ключ.
Отношение — это плоская (двумерная) таблица, состоящая из столбцов и строк:
| ID | Фамилия | Имя | Должность | г.р. |
| 1 | Петров | Игорь | Директор | 1968 |
| 2 | Иванов | Олег | Юрист | 1973 |
| 3 | Ким | Елена | Бухгалтер | 1980 |
| 4 | Сенин | Илья | Менеджер | 1981 |
| 5 | Васин | Сергей | Менеджер | 1978 |
Атрибут — это поименованный столбец отношения.
Домен — это набор допустимых значений для одного или нескольких атрибутов.
Кортеж — это строка отношения.
Степень определяется количеством атрибутов, которое оно содержит
Кардинальность — это количество кортежей, которое содержит отношение.
Первичный ключ — это уникальный идентификатор для таблицы.
Соответствие между формальными терминами реляционной модели данных и неформальными:
- отношение (формальный термин) — таблица (неформальный термин);
- атрибут — столбец;
- кортеж — строка или запись;
- степень — количество столбцов;
- кардинальное число — количество строк;
- первичный ключ — уникальный идентификатор;
- домен — общая совокупность допустимых значений.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.
Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
Итак, наша база данных фактически готова. Схематично она выглядит так:
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Как узнать настоящую реляционную БД
Таблицы реляционной базы имеют ряд отличительных особенностей. В первую очередь это особая структура. Каждая строка таблицы уникальна, не может быть двух одинаковых. Столбцы имеют строгую упорядоченность.
Наличие хотя бы одного столбца обязательное условие, даже если в таблице совсем нет строк. Каждый столбец так же должен быть с уникальным обозначением и содержать только один тип данных — дату, текст или число.

Каждая ячейка таблицы содержит только единое значение, без каких либо подгрупп
Также важной отличительной чертой реляционной базы является универсальность. Правильно организованная БД не зависит от аппаратного обеспечения компьютеров и от способов хранения информации
К тому же не должно иметь значение, хранится ли база на одном компьютере или на нескольких.
Что такое нереляционная база данных
Реляционная база данных не эффективна для хранения большого количества данных, таких как BigData. Нереляционная база данных является решением этой проблемы. Кроме того, нереляционная база данных также называется NoSQL, Эти базы данных могут хранить большие данные. Также возможно кластеризовать данные на несколько машин, чтобы снизить затраты на обслуживание.

Существуют различные типы нереляционных баз данных.
Базы документов — Хранить динамические данные. Они хранят данные в формате JavaScript Object Notation (JSON). Например. CouchDB, Монго
Базы данных столбцов — Чтение и запись данных столбца мудро. Это полезно в аналитике данных. Например. Апач Кассандра.
Значение ключа хранимых баз данных — Быстро и не очень настраиваемый. Например. Couchbase Server, Redis.
Кэш базы данных — Храните данные на диске или в кеше. Например. Memcache
Граф базы данных — состоят из узлов. Отношения создаются с использованием ребер. Например. Oracle NoSQL, Neo4J.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Реляционные операции
Запросы, сделанные к реляционной базе данных, и производные реляционные переменные в базе данных выражаются в реляционном исчислении или реляционной алгебре . В своей первоначальной реляционной алгебре Кодд ввел восемь реляционных операторов в две группы по четыре оператора в каждой. Первые четыре оператора были основаны на традиционных математических операциях над множеством :
- Оператор объединения объединяет кортежи двух отношений и удаляет все повторяющиеся кортежи из результата. Оператор реляционного объединения эквивалентен оператору SQL UNION .
- Оператор пересечения создает набор кортежей, которые являются общими для двух отношений. Пересечение реализовано в SQL в виде оператора INTERSECT .
- Оператор разности воздействует на два отношения и создает набор кортежей из первого отношения, которых нет во втором отношении. Различие реализовано в SQL в виде оператора EXCEPT или MINUS.
- Декартово произведение двух отношений является объединение , которое не ограничивается каким — либо критериям, в результате чего в каждом наборе из первого соотношения, совпадающим с каждым кортежем второго соотношения. Декартово произведение реализовано в SQL как оператор перекрестного соединения .
Остальные операторы, предложенные Коддом, включают специальные операции, характерные для реляционных баз данных:
- Операция выбора или ограничения извлекает кортежи из отношения, ограничивая результаты только теми, которые соответствуют определенному критерию, то есть подмножеством с точки зрения теории множеств. Эквивалентом выбора в SQL является оператор запроса SELECT с предложением WHERE .
- Операция проецирования извлекает только указанные атрибуты из кортежа или набора кортежей.
- Операция соединения, определенная для реляционных баз данных, часто называется естественным соединением. В этом типе соединения два отношения связаны своими общими атрибутами. MySQL аппроксимация естественного соединения — это оператор внутреннего соединения . В SQL INNER JOIN предотвращает появление декартова произведения, когда в запросе есть две таблицы. Для каждой таблицы, добавленной в SQL-запрос, добавляется одно дополнительное ВНУТРЕННЕЕ СОЕДИНЕНИЕ, чтобы предотвратить декартово произведение. Таким образом, для N таблиц в запросе SQL должно быть N − 1 INNER JOINS, чтобы предотвратить декартово произведение.
- Операция является немного более сложной операцией и по существу включает в себя использование кортежей одного отношения (делимого) для разделения второго отношения (делителя). Оператор реляционного деления фактически противоположен оператору декартового произведения (отсюда и название).
Другие операторы были введены или предложены после того, как Кодд представил первоначальную восьмерку, включая операторы реляционного сравнения и расширения, которые, среди прочего, предлагают поддержку вложенности и иерархических данных.
Калькулятор расчета пенсии
Жесткие диски цены
Доля рынка
Согласно DB-Engines , в июле 2019 года наиболее широко используемыми системами были Oracle , MySQL ( бесплатное программное обеспечение ), Microsoft SQL Server , PostgreSQL (бесплатное программное обеспечение), IBM DB2 , Microsoft Access , SQLite (бесплатное программное обеспечение) и MariaDB (бесплатное программное обеспечение). программное обеспечение).
По данным исследовательской компании Gartner , в 2011 году в пятерку ведущих производителей реляционных баз данных проприетарного ПО по объему выручки входили Oracle (48,8%), IBM (20,2%), Microsoft (17,0%), SAP, включая Sybase (4,6%) и Teradata (3,7 %). %).
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
Особенности, структура и термины, связанные с реляционной моделью
Каждый источник по-своему описывает ее элементы, поэтому для меньшей путаницы хотелось бы привести небольшую подсказку:
- реляционная табличка = сущность;
- макет = атрибуты = наименование полей = заголовок столбцов сущности;
- экземпляр сущности = кортеж = запись = строка таблички;
- значение атрибута = ячейка сущности= поле.
Для перехода к свойствам реляционной базы данных следует знать, из каких базовых компонентов она состоит и для чего они предназначены.
- Сущность. Таблица реляционной базы данных может быть одна, а может быть целый набор из таблиц, которые характеризируют описанные объекты благодаря хранящимся в них данным. У них фиксированное количество полей и переменное число записей. Таблица реляционной модели баз данных составляется из строк, атрибутов и макета.
- Запись – переменное число строк, отображающих данные, что характеризируют описываемый объект. Нумерация записей производится системой автоматически.
- Атрибуты — данные, демонстрирующие собой описание столбцов сущности.
- Поле. Представляет собой столбец сущности. Их количество – фиксированная величина, устанавливаемая во время создания или изменения таблицы.
Теперь, зная составляющие элементы таблицы, можно переходить к свойствам реляционной модели database:
- Сущности реляционной БД двумерные. Благодаря этому свойству с ними легко проделывать различные логические и математические операции.
- Порядок следования значений атрибутов и записей в реляционной таблице может быть произвольным.
- Столбец в пределах одной реляционной таблицы должен иметь свое индивидуальное название.
- Все данные в столбце сущности имеют фиксированную длину и одинаковый тип.
- Любая запись в сущности считается одним элементом данных.
- Составляющие компоненты строк единственны в своем роде. В реляционной сущности отсутствуют одинаковые строки.
Исходя из свойств реляционной СУБД, понятно, что значения атрибутов должны быть одинакового типа, длины. Рассмотрим особенности значений атрибутов.
Реляционная модель
У реляционной модели есть несколько ограничений. Одним из главных является ограниченность в возможностях представления сущностей реального мира, которые имеют гораздо более сложный вид, чем тот, в котором их можно представить с помощью кортежей и отношений. Еще более слабой эта модель является в том, что касается различения разных видов отношений между сущностями. Представлять сложные данные и манипулировать ими в традиционных реляционных базах данных не возможно: набор операций, которые можно выполнять в реляционных моделях, не подходит для многих реальных приложений, в состав которых входят объекты с нечисловыми атрибутами.
Ограничения традиционной реляционной модели при моделировании нескольких сущностей реального мира привели к изучению семантических моделей данных и так называемых расширенных реляционных моделей данных. За право считаться следующим поколением реляционной модели сейчас соревнуются две модели: объектно-ориентированная и объектно-реляционная. Базы данных, разрабатываемые на основе первой, называются объектно-ориентированными системами управления базами данных (ООСУБД; Object-Oriented Database Management Systems — OODBMS), а базы данных,разрабатываемые на основе второй, соответственно — объектно-реляционными системами управления базами данных.
Базовые и производные отношения
В реляционной базе данных все данные хранятся и доступны через отношения . Отношения, в которых хранятся данные, называются «базовыми отношениями», а в реализациях — «таблицами». Другие отношения не хранят данные, но вычисляются путем применения реляционных операций к другим отношениям. Эти отношения иногда называют «производными отношениями». В реализациях они называются « представлениями » или «запросами». Производные отношения удобны тем, что действуют как одно отношение, даже если они могут получать информацию из нескольких отношений. Кроме того, производные отношения могут использоваться в качестве уровня абстракции .
Домен
Домен описывает набор возможных значений для данного атрибута и может считаться ограничением на значение атрибута. Математически присоединение домена к атрибуту означает, что любое значение атрибута должно быть элементом указанного набора. Например, символьная строка «ABC» находится не в целочисленной области, а целочисленное значение 123 . Другой пример домена описывает возможные значения для поля «CoinFace» как («Головы», «Решки»). Таким образом, поле CoinFace не принимает входные значения, такие как (0,1) или (H, T).
Терминология
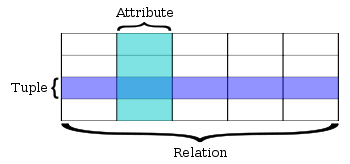
Терминология реляционной базы данных
Реляционная база данных была впервые определена в июне 1970 года Эдгаром Коддом из исследовательской лаборатории IBM в Сан-Хосе . Взгляд Кодда на то, что квалифицируется как СУБД, резюмируется в 12 правилах Кодда . Реляционная база данных стала преобладающим типом базы данных. Другие модели, помимо реляционной, включают иерархическую модель базы данных и сетевую модель .
В таблице ниже приведены некоторые из наиболее важных терминов реляционных баз данных и соответствующие термины SQL :
| Термин SQL | Термин реляционной базы данных | Описание |
|---|---|---|
| Строка | Кортеж или запись | Набор данных, представляющий один элемент |
| Столбец | Атрибут или поле | Помеченный элемент кортежа, например «Адрес» или «Дата рождения». |
| Таблица | Отношение или базовая relvar | Набор кортежей с одинаковыми атрибутами; набор столбцов и строк |
| Просмотр или набор результатов | Производный relvar | Любой набор кортежей; отчет с данными из СУБД в ответ на запрос |
Структура реляционной таблицы
Структуру реляционной таблицы определяет состав полей. В каждом поле отражается определенная характеристика сущности. Для каждого поля указывают размер и тип элементарного данного, которое размещается в нем, и другие свойства. В столбце таблицы отображается содержимое поля и содержатся данные одного и того же типа.
Содержание таблицы заключается в ее однотипных по структуре строках. В каждой строке таблицы, которая называется записью, содержатся данные о конкретном экземпляре сущности.
Чтобы однозначно определить (идентифицировать) каждую запись, у таблицы должен быть первичный (уникальный) ключ. Значение ключа таблицы однозначно определяет запись в таблице. В составе ключа может быть одно или более полей таблицы. Значение уникального ключа не повторяется в нескольких записях.
С помощью логических связей между таблицами можно выполнять объединение данных из разных таблиц. Связь каждой пары таблиц обеспечивают одинаковые поля в них – ключ связи.
Связь двух таблиц В нормализованной реляционной БД характеризуется чаще всего отношениями записей двух типов: «один-к-одному» (1:1) и «один-ко-многим» (1:M).
При связи 1:1 каждой записи одной таблицы ставится в соответствие одна запись другой.
При связи типа 1:М каждой записи первой таблицы ставится в соответствие много записей второй, но каждой записи второй таблицы ставится в соответствие лишь одна запись первой.
Для двух таблиц, которые характеризуются связью типа 1:M, она устанавливается по уникальному ключу главной таблицы (представляет в отношении сторону «один»). Во второй таблице, которая представляет в отношении сторону «многие» и называется подчиненной, данный ключ связи может не входить в состав уникального ключа или являться его частью. Ключ связи подчиненной таблицы еще называют внешним ключом.
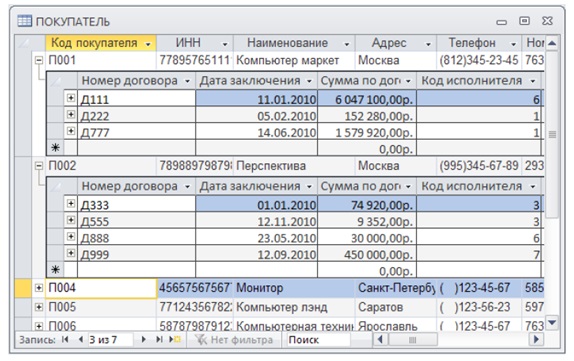
На рисунке 1 представлены 2 таблицы, которые содержат список покупателей и перечень заключенных договоров. Таблицы связаны отношением типа 1:M и логически связаны общим полем (столбцом) Код покупателя, которое является ключом связи. Данное поле –уникальный ключ в главной таблице ПОКУПАТЕЛЬ и неключевое поле в подчиненной таблице ДОГОВОР.
Если хранить данные в двух таблицах, сведения о покупателе будут храниться в одном экземпляре, а в таблице договоров будут повторяться лишь значения ключевого поля, содержащего код покупателя.
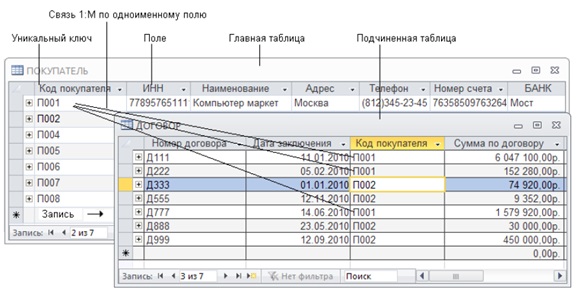
Access содержит средство редактирования и просмотра связанных записей нескольких таблиц. Если раскрыть один уровень иерархии, рядом с записью главной таблицы будут отображаться связанные записи подчиненной. К примеру, для таблиц ДОГОВОР и ПОКУПАТЕЛЬ (рисунок 2), которые связаны отношением 1:М, для каждой записи таблицы ПОКУПАТЕЛЬ можно отобразить и отредактировать связанные записи в таблице ДОГОВОР.
История разработки
Реляционная база данных СУБД была изобретена в начале 1970-х Э. Ф. Коддом, молодым ученым-программистом IBM. В специальной статье по РБД он предложил перейти от хранения данных в иерархических структурах к организации их в таблицах, имеющих строки и столбцы.
К 1960-м годам собралось огромное количество данных, хранящихся на новых мэйнфрейм-компьютерах мира, многие из которых были компьютерами IBM System 360. Это стало проблемой для дальнейшего развития цифровых технологий. Расчеты на мэйнфреймах были дорогими, часто стоили сотни долларов в минуту. Существенной частью этих затрат была сложность, связанная с управлением базой данных (БД).
В 1973 году лаборатория Сан-Хосе, ныне Almaden, начала разрабатывать программу под названием System R (реляционый) с целью применить теорию отношений с помощью так называемой промышленной реализации. Это качество стало определяющим, чтобы определить, какие СУБД называются реляционными. В результате реализации этого проекта было изобретена новая революционная система хранения, ставшая основой успеха IBM.
Дон Чемберлин и Рэй Бойс изобрели SQL для структурированных данных, который сегодня наиболее широко применяются. Патриция Селингер разработала оптимизатор на основе затрат, делающий работу с реляционными БД более рентабельной и эффективной. А Раймон Лори изобрел компилятор, сохраняющий процедуры запросов к БД для будущего использования.
В 1983 году IBM представила второе семейство реляционных СУБД DB2 с целью управления данными. Сегодня DB2 по-прежнему производят миллиарды транзакций каждый день, являясь самым успешным программным продуктом IBM. По словам Арвинда Кришны, генерального менеджера IBM Information Management, DB2 продолжает оставаться лидером в области инновационного ПО для реляционных баз данных (РБД).
Доктор Кодд, известный своим коллегам как Тед, был удостоен звания стипендиата IBM в 1976 году, а в 1981 году Ассоциация вычислительной техники вручила ему премию Тьюринга за вклад, внесенный в разработку РБД.
Структурная таблица
Таблица — это логическая структура, состоящая из строк и столбцов. Строки не имеют фиксированного порядка, поэтому, если извлекаются данные, может понадобиться отсортировать их. Порядок столбцов указывается при создании таблицы администратором БД. На пересечении каждого столбца и строки находится определенный элемент данных, называемый значением, или, точнее, атомарным значением. Таблица именуется высокоуровневым классификатором идентификатора пользователя владельца, за которым следует имя таблицы, например TEST.DEPT или PROD.DEPT.
Существует нескольких типов таблиц:
- Базовая, которая создается и содержит постоянные данные.
- Временная, в которой хранятся промежуточные результаты запроса.
Элементы таблиц:
- Столбцы имеют упорядоченный набор: DEPTNO, DEPTNAME, MGR и ADMK DEPT. Все они должны быть однотипными данными.
- Строки — каждая содержит данные для одного отдела.
- Значения на пересечении столбца и строки. Например, PLANNING — это значение столбца DEPT NAME в строке для отдела B01.
Индекс — это упорядоченный набор указателей на строки таблицы. В отличие от строк таблицы, которые не находятся в определенном порядке, индекс DB2 должен всегда поддерживать порядок.
Индекс используется для двух целей:
- Для повышения быстродействия получения значений данных.
- Для уникальности.
Создав индекс по имени сотрудника, можно получить данные для этого сотрудника быстрее, чем сканируя всю таблицу. Кроме того, создавая его, DB2 обеспечит уникальность каждого значения. Создание индекса автоматически создает индексное пространство, набор данных, который его содержит.
Итоги
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.