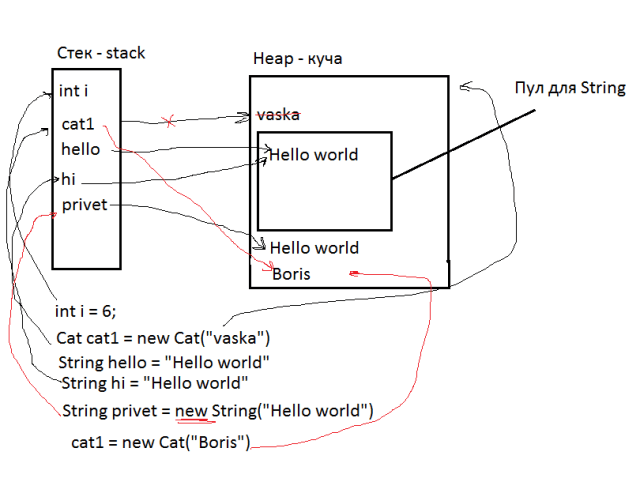
Java regular expression tester
Содержание:
- Введение в регулярные выражения
- Введение в регулярные выражения
- Жадность¶
- Задачка на проверку телефонов
- Как они работают?¶
- Метасимволы
- Брокер — это не навсегда. Не понравится — найдете другого
- Получение целых чисел
- Отличие «preg_match» от «preg_match_all»
- Заметки о методах
- Строковые методы, поиск и замена
- Синтаксис регулярных выражений
- Модификаторы¶
- Использование нумирации в заменах и другие продвинутые возможности
- Функции для работы с регулярными выражениями
Введение в регулярные выражения
Регулярные выражения, также называемые regex, используются практически во всех языках программирования. В python они реализованы в стандартном модуле .
Он широко используется в естественной обработке языка, веб-приложениях, требующих проверки ввода текста (например, адреса электронной почты) и почти во всех проектах в области анализа данных, которые включают в себя интеллектуальную обработку текста.
Эта статья разделена на 2 части.
Прежде чем перейти к синтаксису регулярных выражений, для начала вам лучше понять, как работает модуль .
Итак, сначала вы познакомитесь с 5 основными функциями модуля , а затем посмотрите, как создавать регулярные выражения в python.
Узнаете, как построить практически любой текстовый шаблон, который вам, скорее всего, понадобится при работе над проектами, связанными с поиском текста.
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
-
Набор управляющих кодов для идентификации специфических типов символов
-
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
-
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
-
Сделать заглавными первые буквы всех слов
-
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
-
Обеспечить правильную капитализацию предложений
-
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша (\) и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Метасимволы, используемые в регулярных выражениях C#
Символ
Значение
Пример
Соответствует
Классы символов
Любой из символов, указанных в скобках
В исходной строке может быть любой символ английского алфавита в нижнем регистре
Любой из символов, не указанных в скобках
В исходной строке может быть любой символ кроме цифр
.
Любой символ, кроме перевода строки или другого разделителя Unicode-строки
\w
Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п.
\W
Любой символ, не являющийся текстовым символом
\s
Любой пробельный символ из набора Unicode
\S
Любой непробельный символ из набора Unicode
Обратите внимание, что символы \w и \S — это не одно и то же
\d
Любые ASCII-цифры. Эквивалентно
\D
Любой символ, отличный от ASCII-цифр
Эквивалентно
Символы повторения
{n,m}
Соответствует предшествующему шаблону, повторенному не менее n и не более m раз
s{2,4}
«Press», «ssl», «progressss»
{n,}
Соответствует предшествующему шаблону, повторенному n или более раз
s{1,}
«ssl»
{n}
Соответствует в точности n экземплярам предшествующего шаблона
s{2}
«Press», «ssl», но не «progressss»
?
Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным
Эквивалентно {0,1}
+
Соответствует одному или более экземплярам предшествующего шаблона
Эквивалентно {1,}
*
Соответствует нулю или более экземплярам предшествующего шаблона
Эквивалентно {0,}
Символы регулярных выражений выбора
|
Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ).
(…)
Группировка. Группирует элементы в единое целое, которое может использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках.
(?:…)
Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе.
Якорные символы регулярных выражений
^
Соответствует началу строкового выражения или началу строки при многострочном поиске.
^Hello
«Hello, world», но не «Ok, Hello world» т.к. в этой строке слово «Hello» находится не в начале
$
Соответствует концу строкового выражения или концу строки при многострочном поиске.
Hello$
«World, Hello»
\b
Соответствует границе слова, т.е. соответствует позиции между символом \w и символом \W или между символом \w и началом или концом строки.
\b(my)\b
В строке «Hello my world» выберет слово «my»
\B
Соответствует позиции, не являющейся границей слов.
\B(ld)\b
Соответствие найдется в слове «World», но не в слове «ld»
Жадность¶
Регулярные выражения называются жадными по умолчанию.
Что это значит?
Возьмём например это регулярное выражение:
Предполагается, что нам нужно извлечь из строки сумму в долларах:
но что если у нас есть больше слов после числа, это отвлекает
Почему? Потому что регулярное выражение после знака совпадает с любым символом и не останавливается пока не достигнет конца строки. Затем он останавливается, потому что делает конечное пространство необязательным.
Чтобы исправить это, нам нужно указать что регулярное выражение должно быть ленивым и найти наименьшее количество совпадений. Мы можем сделать это с помощью символа после квантификатора:
Итак, символ может означать разные вещи в зависимости от своего положения, поэтому он может быть и квантификатором и индикатором ленивого режима.
Задачка на проверку телефонов
Задачу надо проверить на большом числе телефонов,
чтобы убедиться что твой код правильный. Для этого давай добавим в программу
тесты, чтобы сразу было видно, верно все работает или нет.
Сделай 2 списка номеров (правильные и нет), добавь их в программу и напиши цикл,
который их по очереди прогоняет через регулярку и проверяет,
что они определяются как надо (если нет — надо вывести, какой именно номер
не распознается правильно).
Вот список номеров:
// Правильные: $correctNumbers = ; // Неправильные: $incorrectNumbers = [ '02', '84951234567 позвать люсю', '849512345', '849512345678', '8 (409) 123-123-123', '7900123467', '5005005001', '8888-8888-88', '84951a234567', '8495123456a', '+1 234 5678901', /* неверный код страны */ '+8 234 5678901', /* либо 8 либо +7 */ '7 234 5678901' /* нет + */ ];
Подсказка: не надо строить сложных выражений и предусматривать все
возможные комбинации символов. Достаточно написать:
Как они работают?¶
Регулярное выражение, которое мы определили выше как , очень простое. Оно ищет строку без каки-либо ограничений: строка может содержать много текста, а слово находиться где-то в середине и регулярное выражение сработает. Строка может содержать только слово и регулярка опять сработает.
Это довольно просто.
Вы можете попробовать протестировать регулярное выражение с помощью метода , который возвращает логическое () значение:
В примере выше мы просто проверили удовлетворяет ли шаблону регулярного выражения, который храниться в .
Это проще простого, но вы уже знаете много о регулярных выражениях.
Метасимволы
| Символ | Описание |
|---|---|
| . | Позволяет найти один символ, кроме символа новой строки, или символа конца строки (\n, \r, \u2028 или \u2029). |
| \d | Позволяет найти символ цифры в базовом латинском алфавите. Эквивалентин использованию набору символов . |
| \D | Позволяет найти любой символ, который не является цифрой в базовом латинском алфавите. Эквивалентен набору символов . |
| \s | Позволяет найти одиночный пробельный символ. Под пробельным символом понимается пробел, табуляция, перевод страницы, перевод строки и другие пробельные символы Юникода. Эквивалентен набору символов . |
| \S | Позволяет найти одиночный символ, который не является пробельным. Под пробельным символом понимается пробел, табуляция, перевод страницы, перевод строки и другие пробельные символы Юникода. Эквивалентен набору символов . |
| Позволяет найти символ backspace (специальный символ \b, U+0008). | |
| \0 | Позволяет найти символ 0 (ноль). |
| \n | Позволяет найти символ новой строки. |
| \f | Позволяет найти символ перевода страницы. |
| \r | Позволяет найти символ возврата каретки. |
| \t | Позволяет найти символ горизонтальной табуляции. |
| \v | Позволяет найти символ вертикальной табуляции. |
| \w | Позволяет найти любой буквенно-цифровой символ базового латинского алфавита, включая подчеркивание. Эквивалентен набору символов . |
| \W | Позволяет найти любой символ, который не является символом из базового латинского алфавита. Эквивалентен набору символов . |
| \cX | Позволяет найти контрольный символ в строке. Где X — буква от A до Z. Например, /\cM/ обозначает символ Ctrl-M. |
| \xhh | Позволяет найти символ, используя шестнадцатеричное значение (hh — двухзначное шестнадцатеричное значение). |
| \uhhhh | Позволяет найти символ, используя кодировку UTF-16 (hhhh — четырехзначное шестнадцатеричное значение). |
| \u{hhhh} или \u{hhhhh} | Позволяет найти символ со значением Юникода U+hhhh или U+hhhhh (шестнадцатеричное значение). Только когда задан флаг u. |
| \ | Указывает, что следующий символ является специальным и не должен интерпретироваться буквально. Для символов, которые обычно трактуются специальным образом, указывает, что следующий символ не является специальным и должен интерпретироваться буквально. |
Брокер — это не навсегда. Не понравится — найдете другого
Получение целых чисел
Как видно из примера, стоимость расходов может состоять из целого числа (два обеда) или это может быть число с плавающей запятой (кофе и кусок торта). Приведенный ниже паттерн соответствует стоимости, состоящей из целочисленной стоимости:
Паттерн для извлечения целочисленной стоимости
Красная пунктирная линия поставлена только для наглядного разделения частей паттерна.
Карет () обозначает начало строки, то есть какой бы текст мы не сопоставляли, символ должен находиться в начале строки. Символ , заключенный в квадратные скобки, означает, что мы сопоставляем цифры (от 0 до 9), а используется для сопоставления одной или нескольких цифр. Без знака паттерн соответствовал бы только единице из стоимости первого обеда, а не его правильной стоимости — 12.
На следующих изображениях показан результат (не) использования квантификатора . Все паттерны я тестирую на сайте regex101.com:
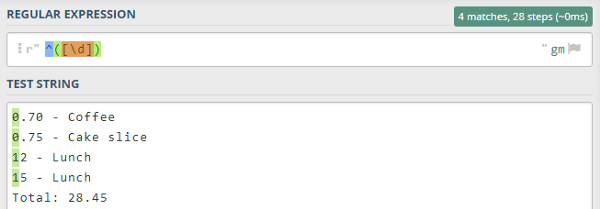
Целочисленный паттерн без теста квантификатором
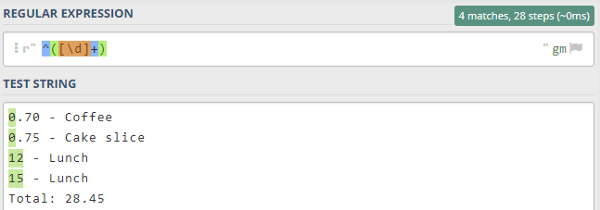
Целочисленный паттерн после теста квантификатором
Что касается квадратных и круглых скобок, то первый тип используется для применения правила знака плюс “сопоставить одну или несколько цифр” к цифрам. Второй же используется для создания правильной группы регулярных выражений. Проще говоря, на группы можно ссылаться отдельно для каждого соответствия. Но к этой теме вернемся в конце, когда будем рассматривать скрипты Python.
Отличие «preg_match» от «preg_match_all»
Функция «preg_match» осуществляет поиск только до первого соответсвия с маской. Как только что-то найдено — поиск останавливается и возвращается одномерный массив.
if (preg_match('|<title>(.+)</title>|isU', $sContent, $arr))
return $arr; else return false;
Здесь нулевой элемент массива «$arr» содержит найденное совпадение вместе с тегами «title», а первый элемент — «$arr» только текст между этими тегами. Если в строке несколько тегов «title», это не значит что остальные значения будут записаны в «$arr» и так далее. Элемент «$arr» окажется не пуст если в маске указано несколько правил, но об этом в следующий раз.
Заметки о методах
Для работы с регулярными выражениями используется семь методов. Начнем разбор по порядку.
Search ()
Используется для нахождения позиции вхождения первого совпадения.
1 2 3 4 5 6 |
<script> var regExp = /рыб/gi; var text = "Покупайте речную рыбу!"; var myArray = text.search(regExp ); alert(myArray); //Ответ: 17 </script> |
Match ()
Работает в двух режимах в зависимости от того, укажете ли вы опциональный флаг g или нет.
Если /g отсутствует, то в результате будет получен массив из одного элемента и с возможностью просмотра дополнительных свойств input (строка, в которой осуществлялся поиск совпадений) и index (позиция результата; если подстрока не найдена, то покажет -1).
1 2 3 4 5 6 7 8 |
<script> var regExp = /12.02/; var text = "11.02 - Концерт. 12.02 - Мастер-класс."; var myArray = text.match(regExp ); alert( myArray ); alert( myArray.input ); //11.02 - Концерт. 12.02 - Мастер-класс. alert( myArray.index ); //17 </script> |
Если же вы используете глобальный поиск, то возможность просмотра дополнительных свойств пропадает, а в массиве вернутся все совпадения.
Split ()
Как и в некоторых других языках программирования, метод Split () разбивает значение строковой переменной на подстроки по заданному разделителю.
1 2 3 4 |
<script>
var text = "Пусть все будет хорошо";
alert(text.split(' ')); //Пусть,все,будет,хорошо
</script>
|
В качестве разделителя можно передавать как строковое значение, так и регэксп.
Replace ()
Очень удобный инструмент для нахождения и замены символов в задачах различной сложности. По умолчанию изменяет только первое совпавшее вхождение, однако это исправимо благодаря такой удобной штуке, как /g.
1 2 3 4 |
<script> var text = "Ты пробежал 3 км за 13 и 25 минут."; alert( text.replace( / и /g, "," )); // Ты пробежал 3 км за 13,25 минут </script> |
Exec ()
До этого все методы принадлежали к классу String. А оставшиеся два предоставляются классом RegExp.
Итак, текущий метод является дополнением к первым двум описанным методам. Он также ищет все вхождения и еще скобочные группы. Без указания флага g exec () работает, как match (). В противном случае совпадение запоминается, а его позиция записывается в lastIndex.
Последующий поиск продолжается с установленной позиции. Если далее совпадений больше не было, то lastIndex сбрасывается в 0.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<script>
var str = 'Сорок сорок сидели на трубе';
var expresion = /сорок/ig;
var res;
alert( "lastIndex: " + expresion.lastIndex );
while (res = expresion.exec(str)) {
alert( 'Найдено: ' + res + ' на позиции: ' + res.index );
alert( 'А теперь lastIndex равен: ' + expresion.lastIndex );
}
alert( 'Под конец lastIndex сбрасывается в: ' + expresion.lastIndex );
</script>
|
Test ()
Данный инструмент проверяет, а есть ли хоть один результат совпадения строк. Если есть, то возвращает булево значение true, иначе – false.
1 2 3 4 |
<script>
var expresion = /крас/gi;
alert( expresion.test("Ах, какая красна девица! красавица!")); //true
</script>
|
Вот я и рассказал вам основы такого механизма, как регулярные выражения. Для лучшего усвоения материала читайте и другие статьи на данную тематику на моем блоге, а также становитесь подписчиками и делитесь интересными ссылками с друзьями. Пока-пока!
Прочитано: 119 раз
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Синтаксис регулярных выражений
Последнее обновление: 1.11.2015
Рассмотрим базовые моменты синтаксиса регулярных выражений.
Метасимволы
Регулярные выражения также могут использовать метасимволы — символы, которые имеют определенный смысл:
-
: соответствует любой цифре от 0 до 9
-
: соответствует любому символу, который не является цифрой
-
: соответствует любой букве, цифре или символу подчеркивания (диапазоны A–Z, a–z, 0–9)
-
: соответствует любому символу, который не является буквой, цифрой или символом подчеркивания (то есть не находится в следующих диапазонах A–Z, a–z, 0–9)
-
: соответствует пробелу
-
: соответствует любому символу, который не является пробелом
-
: соответствует любому символу
Здесь надо заметить, что метасимвол \w применяется только для букв латинского алфавита, кириллические символы для него не подходят.
Так, стандартный формат номера телефона соответствует регулярному выражению .
Например, заменим числа номера нулями:
var phoneNumber = «+1-234-567-8901»; var myExp = /\d-\d\d\d-\d\d\d-\d\d\d\d/; phoneNumber = phoneNumber.replace(myExp, «00000000000»); document.write(phoneNumber);
Модификаторы
Кроме выше рассмотренных элементов регулярных выражений есть еще одна группа комбинаций, которая указывает, как символы в строке будут повторяться. Такие комбинации еще называют модификаторами:
-
: соответствует n-ому количеству повторений предыдущего символа. Например, соответствует подстроке «hhh»
-
: соответствует n и более количеству повторений предыдущего символа. Например, соответствует подстрокам «hhh», «hhhh», «hhhhh» и т.д.
-
: соответствует от n до m повторений предыдущего символа. Например, соответствует подстрокам «hh», «hhh», «hhhh».
-
: соответствует одному вхождению предыдущего символа в подстроку или его отсутствию в подстроке. Например, соответствует подстрокам «home» и «ome».
-
: соответствует одному и более повторений предыдущего символа
-
: соответствует любому количеству повторений или отсутствию предыдущего символа
-
: соответствует началу строки.
Например, соответствует строке «home», но не «ohma», так как h должен представлять начало строки
-
: соответствует концу строки. Например, соответствует строке «дом», так как строка должна оканчиваться на букву м
Например, возьмем номер тот же телефона. Ему соответствует регулярное выражение . Однако с помощью выше рассмотренных комбинаций мы его можем упростить:
Также надо отметить, что так как символы ?, +, * имеют особый смысл в регулярных выражениях, то чтобы их использовать в обычным для них значении (например, нам надо заменить знак плюс в строке на минус), то данные символы надо экранировать с помощью слеша:
var phoneNumber = «+1-234-567-8901»; var myExp = /\+\d-\d{3}-\d{3}-\d{4}/; phoneNumber = phoneNumber.replace(myExp, «80000000000»); document.write(phoneNumber);
Отдельно рассмотрим применение комбинации ‘\b’, которая указывает на соответствие в пределах слова. Например, у нас есть следующая строка: «Языки обучения: Java, JavaScript, C++». Со временем мы решили, что Java надо заменить на C#. Но простая замена приведет также к замене строки «JavaScript» на «C#Script», что недопустимо. И в этом случае мы можем проводить замену, если регуляное выражение соответствует всему слову:
var initialText = «Языки обучения: Java, JavaScript, C++»; var exp = /Java\b/g; var result = initialText.replace(exp, «C#»); document.write(result); // Языки обучения: C#, JavaScript, C++
Но при использовании ‘\b’ надо учитывать, что в JavaScript отсутствует полноценная поддержка юникода, поэтому применять ‘\b’ мы сможем только к англоязычным словам.
Использование групп в регулярных выражениях
Для поиска в строке более сложных соответствий применяются группы. В регулярных выражениях группы заключаются в скобки. Например, у нас есть следующий код html, который содержит тег изображения: ‘<img src=»https://steptosleep.ru/wp-content/uploads/2018/06/47616.png» />’. И допустим, нам надо вычленить из этого кода пути к изображениям:
var initialText = ‘<img src= «picture.png» />’; var exp = /+\.(png|jpg)/i; var result = initialText.match(exp); result.forEach(function(value, index, array){ document.write(value + «<br/>»); })
Вывод браузера:
picture.png png
Первая часть до скобок (+\.) указывает на наличие в строке от 1 и более символов из диапазона a-z, после которых идет точка. Так как точка является специальным символом в регулярных выражениях, то она экранируется слешем. А дальше идет группа: . Эта группа указывает, что после точки может использоваться как «png», так и «jpg».
Модификаторы¶
Синтаксис для одного модификатора: чтобы включить, и чтобы выключить. Для большого числа модификаторов используется синтаксис: .
Можно использовать внутри регулярного выражения. Это может быть особенно удобно, поскольку оно имеет локальную область видимости. Оно влияет только на ту часть регулярного выражения, которая следует за оператором .
И если оно находится внутри подвыражения, оно будет влиять только на это подвыражение, а именно на ту часть подвыражения, которая следует за оператором. Таким образом, в это влияет только на подвыражение , поэтому оно будет соответствовать , но не .
Использование нумирации в заменах и другие продвинутые возможности
Теперь немного о продвинутых возможностях функции «preg_replace_callback». Ранее я упоминал что у неё есть два необязательных параметра. Первый (по умолчанию равен «-1») содержит максимальное количество замен, которое должна произвести функция. Второй — переменная, в которую будет записано количество произведенных замен.
$sContent = preg_replace_callback('|(<xx>)(.+)(</xx>)|iU',
function($matches){ //тут код }
,$sContent,2,$count);
Задав эти два параметра в предыдущем примере, замена главной буквы будет произведена только у первых двух имён. Соответственно, переменная «$count» будет содержать — 2. Если установить первый дополнительный параметр в «-1», то «$count» будет — 3.
И в конце о том, как узнать какая по счету замена происходит в данный момент. Это может потребоваться если появилась необходимость произвести замену между пятым и десятым найденным элементом строки или требуется для каких-то тегов прописать уникальные идентификаторы.
Для реализации может быть использована глобальная или статическая переменная. Использование глобальных переменных может быть отключено в PHP, поэтому рассмотрим пример со статической переменной. Присвоим всем тегам h2 уникальный идентификатор.
<?php
$str = '<h2>Марина</h2> <b>Алёша</b> <h2>Наташа</h2> <h2>Катя</h2>';
$str = preg_replace_callback('|<h2>(.+)</h2>|iU', function($matches){
static $id = 0;
$id++;
return '<h2 id="uniq-'.$id.'">'.$matches.'</h2>';
}, $str,-1,$count);
echo $str.' Количество замен: '.$count;
?>
Объявляя статическую переменную нужно помнить что она сохраняет своё значение между вызовами функции, поэтому идеально подходит для решения нашей задачи.
Функции для работы с регулярными выражениями
В PHP есть поддержка 2 типов записи РВ — POSIX и Perl. POSIX (Portable Operating System Interface) представляет собой интерфейс переносной операционной системы и стандарт для интерфейсов приложений. Сейчас мы рассмотрим РВ POSIX и Perl-совместимые РВ.
Скорость выполнения функций для работы с РВ ниже строковых функций, которые обладают аналогичными возможностями. По этой причине лучше использовать строковые функции — если, конечно, ущерба эффективности не наносится.
ereg()
bool ereg(string pattern, string string )
Эта функция осуществляет поиск соответствия РВ в строке string, который задан в шаблоне pattern. В случае наличия соответствий шаблона с подвыражениями их сохранят в массиве соответствий regs. В $regs имеется копия строки string, а в $regs находится подстрока, которая начинается с первой левой скобки. Подстрока со второй левой скобки хранится в $regs и т. д.
Рассмотрим код, который из формата YYYY-MM-DD преобразовывает формат даты в DD.MM.YYYY.
<? $date = "2015-03-21";
if (ereg ("({4})-({1,2})-({1,2})", $date, $regs)){
echo "$regs.$regs.$regs";
}
else{
echo "Неверный формат даты: $date";
}
?>
ereg_replace()
string ereg_replace(string pattern, string replacement, string string)
Данная функция меняет шаблон pattern, который был обнаружен в строке string, на строку replacement. При наличии соответствия происходит осуществление модифицированной строки.
Будьте внимательны: указание числа как типа, который отличен от строкового, является ошибкой — число должно всегда указываться как строка.
<?
$number = "1952";
$str = "Он родился в пятьдесят втором.";
echo("до замены:$str");
$str = ereg_replace("пятьдесят втором", $number, $str);
echo("<br> после замены: $str");
?>
Результат:
до замены: Он родился в пятьдесят втором.после замены: Он родился в 1952.
eregi()
bool eregi (string pattern, string string)
Данная функция аналогична ereg. Отличие состоит в том, что регистр игнорируется.
eregi_replace()
string eregi_replace (string pattern, string replacement, string string)
Отличие данной функции от ereg_replace состоит в том, что она не является чувствительной к регистру.
split()
array split (string pattern, string string )
Данная функция проводит возвращение массива строк из подстрок строк string, которые были образованы в соответствии с РВ pattern в ходе разделения строки string на подстроки. При указании параметра limit (он не является обязательным) возвращаемый массив будет иметь до limit элементов, причем в последнем имеется неразделенная часть строки.
Данная функция окажет пользу при разделении доменных имен, дат и проч. Например:
<?
$url = "www.softtime.ru";
$array = split ("\.", $url);
foreach($array as $index => $val) {
echo("$index -> $val <br />");
}?>
В результате будет следующее:
0 -> www 1 -> softtime 2 -> ru
Это же можно осуществить и с датой:
<?
$date = "10-12-2003"
$array = split ("-", $date);
foreach($array as $index => $val){
echo("$index -> $val <br />");
}
?>
В результате мы получим:
0 -> 10 1 -> 12 2 -> 2015
spliti()
array spliti (string pattern, string string )