Делаем правильно кластеризацию семантического ядра
Содержание:
- Техническое упрощение кластеризации запросов
- Способы кластеризации
- Видео: Намертво зависает компьютер(решение)
- Как группировать ключевые слова
- Что такое Яндекс Wordstat
- Группировка запросов
- Что делать после кластеризации
- Как собирать ключи для СЯ
- Группировка в таблице связок Yagla
- Генерация рекламных текстов для групп объявлений
- Распределение запросов по страницам сайта
- Очистка семантики от мусора и поиск минус-слов
- Способы составления семантического ядра
- Как группировали раньше
- Оффлайн парсеры
Техническое упрощение кластеризации запросов
В этом нам поможет хороший и верный кей коллектор, хотя он, конечно, не сделает за нас нашу работу, но сократит ее как минимум на треть.
По мне так отличная функция. Хоть и не идеальная, но это — хоть что то.
Для максимального эффекта используем формат: «По составу и выдачи»
Силу выставляем или 3/3 или подгоняем под конкретный случай (погрешность зависит от выдачи)
Для максимального эффекта нужно использовать данные из «ВСЕ ПС»
Для этого требуется предварительно их собрать
Все ПС парсятся быстро, для яндекса можно использовать XML, если есть большой запас лимитов. При парсинге гугла можно встретить капчу (при работе без прокси), но при работе через прокси сильно теряем в скорости сбора. Количество капч до смешного мало, потому оптимально собирать в лоб.
После сбора выдачи проводим расчет и получаем достаточно хорошую картину
Рекомендую поиграть на этом этапе с параметрами влияния, на примере первых групп вы сможете найти оптимальный вариант.
Обязательно проставляем галочку:
Иначе при экспорте потеряете те фразы, которые не удалось распределить автоматом.
Я еще раз подчеркну: это не конченый вариант, но он все же сильно упрощает и ускоряет нам работу через автоматизацию.
Что имеем на выходе в файле и дальнейшая работа:
Обратим внимание на группы, подобранные автоматически. Сразу видны огрехи
Красным я выделил фразы которые должны были быть убраны на этапе чистки СЯ , но их проглядели. Поэтому при группировке проводим еще и дочистку СЯ от не целевых запросов. Удаляем такие фразы.
Оранжевым я выделил запросы которые попали не в свою группу. Их необходимо перенести в свою.
Синим я выделил 2 группы которые были разбиты на 2 части, хотя по смыслу они идентичны. Их необходимо слить в единую группу.
Способы кластеризации
При кластеризации на основании топов объединение поисковых запросов может проводиться двумя способами:
- Soft
- Hard
При использовании первого способа за основу группы берется главный ключевой запрос, а остальные сравнивают с ним, анализируя количество общих URL-адресов в выдаче «Яндекса». Дополнительное ключевое слово попадает в группу, если количество общих URL-адресов превышает заданный порог.
При использовании способа хард запросы включаются в одну группу только в том случае, если для всех запросов есть одинаковый набор URL, показываемый по каждому из ключевых слов в выдаче.
Один из главных параметров кластеризации – «порог». Под этим термином подразумевают количество общих URL для получения кластера. Чем он выше, тем более точными получаются кластеры, но тем меньшими они становятся.
Порог:
- Soft – 4 URL
- Hard – 3 URL
При работе с меньшими показателями в группы попадает слишком много неподходящих запросов. Очевидно, что разные способы кластеризации дают разный результат. Так, Soft дает отличные показатели полноты, но недостаточные показатели точности.
Значит ли это, что Soft использовать не стоит? Нет, все зависит от ваших целей. При трафиковом продвижении и необходимости разместить на странице наибольшее количество запросов, Soft будет оптимальным решением. Но в том случае, если на странице вам нужна чистая и очень точная семантика, применять нужно только Hard.
Видео: Намертво зависает компьютер(решение)
Как группировать ключевые слова
Чаще всего в одной группе 2-5 фраз. Не рекомендуем делать больше, так как затем под них сложнее писать релевантные объявления. В следствие этого падает CTR и растет цена за клик.
Рассмотрим методику на примере продажи входных дверей. Вот несколько групп:
Запросы, где пользователи интересуются деревянными входными дверями:
«Деревянные входные двери на заказ»;
«Заказать деревянную входную дверь»;
«Изготовление деревянных входных дверей»;
«Изготовление деревянных входных дверей +на заказ»;
«Изготовление деревянных входных дверей +на заказ недорого»;
Запросы по металлическим входным дверям:
«Заказать металлическую входную дверь»;
«Заказать железную входную дверь»;
«Металлическая входная дверь на заказ»;
«Железная входная дверь на заказ»;
Запросы со словом «изготовление», но без указания типа — деревянные или металлические:
«Изготовление входных дверей недорого»;
«Изготовление входных дверей»;
«Изготовление входных дверей на заказ»;
«Входные двери изготовление на заказ»;
Запросы, которые содержат «на заказ»:
«Купить входную дверь на заказ»;
«Купить входную дверь заказать»;
«Входные двери на заказ недорого»;
«Входные двери на заказ производство»;
и т.д.
По какому принципу мы объединяем ключевики? Смотрим смысловое соответствие. Его суть в следующем: есть слово-локомотив — это общее свойство или признак для группы. Под него подтягиваются все остальные.
Поэтому фразы «Изготовление входных дверей на заказ» и «Входные двери изготовление на заказ» попали в третью группу, где главное слово — «изготовление», а «Купить входную дверь на заказ» и «Входные двери на заказ недорого» — в четвертую, по признаку «На заказ».
Каким способом мы группируем ключевики? Если семантики немного, можно вручную. Для большого объема проводим кластеризацию с помощью таких платных инструментов, как Key Collector, Rush Analytics, PPC Help, Мегалемма. Как и любой автоматический метод, они не дают 100% точности обработки данных, поэтому стоит проверять результаты на смысловое соответствие.
Итак, мы сгруппировали ключевики, теперь переходим к объявлениям.
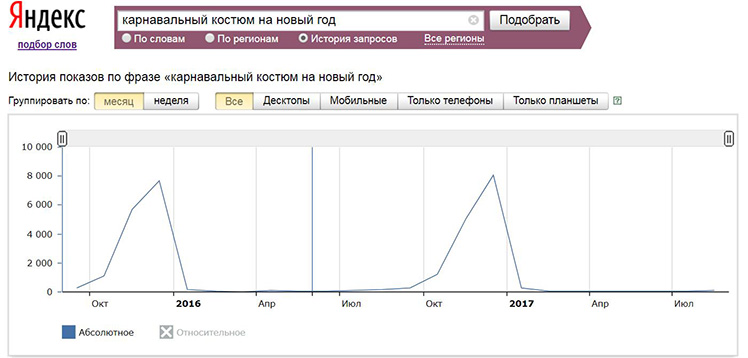
Что такое Яндекс Wordstat
Яндекс Wordstat — бесплатный сервис, предназначенный для сбора статистики поисковых запросов в Яндексе. Он помогает рекламодателям и веб-мастерам понять популярность тех или иных ключей, выявить тренды, а также спрос на товары и услуги.
На деле Wordstat отображает прогнозное количество показов ключа в месяц на основе существующей статистики поиска, не включая РСЯ. В списках приводятся как различные вариации исследуемой фразы, так и те, которые наиболее часто ей сопутствуют. На этой основе можно делать выводы о смежных сферах интересов пользователей, которые затем использовать в кампании.
Благодаря сервису у специалиста появляется возможность:
- Собрать основу семантического ядра;
- Ранжировать популярность запросов по регионам;
- По устройствам;
- Выявить сезонность.
А с Calltouch можно анализировать результаты проделанной работы.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Между тем, существует ряд ограничений на работу с сервисом. Так, для качественного парсинга и анализа всех ключевых слов специалисту придётся использовать дополнительное программное обеспечение или плагины. Дело в том, что поиск по статистике Яндекса возможен только в ручном режиме. Процесс отсеивания и сбора ключевых фраз становится рутинным и трудоёмким в связи с невозможностью их загрузки на компьютер стандартными средствами сервиса. Из-за этого сбор семантического ядра через Wordstat не может быть произведён в полном объёме, если не прибегать к сторонним инструментам.
Вместе с этим, составление ядра затрудняется и ограничением по объёму выдачи. Если ваш запрос имеет много вариаций и весьма популярен в различных формах, вы вероятно не сможете проанализировать и использовать их все. Вордстат позволяет просмотреть лишь 2000 строк результата — 40 страниц по 50 фраз. Если за пределами остаются важные низкочастотные ключи, вы с трудом сможете их достать стандартными средствами.
Более того, для пользования Wordstat вы должны войти в Яндекс аккаунт. Уже в процессе работы с сервисом вы рискуете постоянно вводить капчу и даже быть забаненными в случае злоупотребления поиском однотипных запросов. Чтобы продолжать пользоваться сервисом в нормальном режиме, вы можете попробовать вводить слова в разных падежах. Например: вордстат Яндекс, вордстата Яндекса.
Группировка запросов
После фильтрации запросов нужно посчитать для них отношение БЧ к ТЧ и распределить по смысловым группам.
Отношение базовой частотности к точной показывает насколько эффективным является поисковый запрос. Если значение отношения БЧ к ТЧ большое, скорее всего запрос «пустой» и не стоит его использовать при продвижении страницы сайта.
Процесс группировки запросов занимает большое количество времени, чтобы сократить его, используется приложение «Подбор и кластеризация запросов» от Megaindex. Все что нужно сделать, это ввести доменное имя целевого сайта, добавить свой список запросов и запустить процесс кластеризации. Через некоторое время получается файл с разгруппированными запросами, которые нужно сопоставить с исходным файлом запросов, в котором есть значения частотностей и отношение БЧ к ТЧ. В данном случае пригодится функция ВПР для Excel. Функция позволит найти и перенести искомые значения частотностей из столбцов общего списка запросов в столбцы списка разгруппированных запросов.
Вводим формулу в первую ячейку столбца базовых частотностей:
- искомое значение – нужно выделить первую фразу в столбце кластеризованных запросов;
- таблица – выделить таблицу общего списка запросов;
- номер столбца – ввести номер столбца (например, столбец с базовой частотностью второй);
- интервальный просмотр – поставить 0.
Затем нужно протянуть значения вниз, предварительно поставив знаки доллара у выделенного интервала таблицы.
После того, как все столбцы со значениями будут перенесены, их нужно выделить и нажать копировать. Затем, нажав правую кнопку мышки, выбрать пункт «Специальная вставка» и там выбрать вариант для вставки «значения».
Таким образом перенесенные значения больше не будут ссылаться на искомые и их можно будет удалить.
Когда запросы разбиты на группы, нужно отнести наиболее запрашиваемые в группу «А», а все остальные в группу «Б». Данные запросы будут продвигаться в первую очередь.
Теперь запросам группы «А» назначаются посадочные страницы.
Есть правило — один КС должен соответствовать одной посадочной странице. В одной группе может быть несколько запросов, которые содержат дополнительные слова или похожи между собой и отображают какую-то одну суть.
Например: «циклевка паркета в спб», «циклевка паркета в спб недорого цены», «циклевка пола», «циклевка пола цены спб».
Эти запросы относятся к одной посадочной странице, которая должна быть оптимизирована именно под них и должна быть релевантной, т.е. в полной мере давать ответ на запрос пользователя. Если пользователь не найдет для себя нужной информации и сразу покинет страницу, это будет плохим сигналом для ПС и может плохо повлиять на дальнейшее продвижение сайта.
Что делать после кластеризации
Если вы выбрали автоматическую кластеризацию, данные, полученные в результате использования сервисов или программ, необходимо доработать вручную. В процессе ручной доработки, исходя из логики, какие-то запросы или кластеры удаляются, другие разделяются или, наоборот, объединяются.
Каждой группе соответствует отдельная страница сайта. Для каждой страницы нужно подготовить Title, Description, H1 и URL, в которых будут использованы поисковые запросы из кластера, а также атрибут alt для тега img и предусмотреть использование запросов в других зонах.
Некластеризованные запросы
Запросы, которые не были включены ни в один кластер, удалять не нужно. Вы можете добавить их на отдельные страницы сайта (например, в разделах «Статьи» или «Блог») или включить в какой-то из имеющихся кластеров по смыслу.
Финальная проверка
Финальная проверка делается на этапе составления контент-плана – определяется соответствие запросов в кластере интентам пользователей и возможная полнота раскрытия темы.
Как собирать ключи для СЯ
Как пользоваться Яндекс Вордстат: операторы, расширения и секреты
Кратко о важном: какими операторами пользоваться в Вордстате, чтобы смотреть нужные запросы, и как облегчить себе работу в сервисе.
Вордстат не дает абсолютно точной информации, в нем нет всех запросов, в данные могут быть искажены, потому что Яндексом пользуются не все потребители.Тем не менее, из этих данных можно сделать выводы о популярности темы или товара, приблизительно спрогнозировать спрос, собрать ключи и найти идеи для нового контента.
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
В статье:
- Зачем нужен Вордстат
- Работа с операторами Вордстата
- Как читать данные Wordstat
- Расширения для Яндекс Вордстата
Продвижение сайта по низкочастотным запросам
Компании и веб-мастера стараются продвинуться под популярные запросы, чтобы получить больше трафика. И многие новички совершают ошибку, когда пишут исключительно под ВЧ, попадая при этом в условия огромной конкуренции за 10 мест в поисковой выдаче с тысячами и десятками тысяч сайтов. Исследование на сайте Chitika.com показывает, что сайты за пределами топ-10 не приносят особого трафика.
В статье:
- LT-запросы
- Суть продвижения по низкочастотным запросам
- Преимущества продвижения по низкочастотным запросам
- Как найти и собрать НЧ-запросы
- Способ первый: изучение семантики
- Способ второй: сервисы для анализа ключевых слов
- Как оптимизировать сайт и отдельную страницу под низкочастотные запросы
Подборка инструментов для SEO и LSI-копирайтинга: как собрать и проверить ключи
Делимся подборкой инструментов для сбора LSI-фраз и ключей. Для тех, кто еще не разобрался, рассказываем, в чем все-таки различие между SEO и LSI-копирайтингом, что должно быть в оптимизированных текстах в 2018 году.
В копирайтинге обычно выделяют два вида оптимизированных текстов: по SEO и LSI. Многие не соглашаются с таким делением, потому что эти два способа очень похожи.
SEO больше сосредоточено на работе с поисковыми ботами, а LSI на выдаче пользователям самой полной и полезной информации, повышении качества контента, к чему и стремятся поисковики. Подбирать такие фразы вручную довольно долго. Мы попробовали несколько сервисов, которые предлагают подобрать SEO и LSI-ключевики, чтобы дело шло быстрее.
В статье:
- Что такое LSI-ключи
- SEO и LSI — в чем разница
- Как искать LSI-фразы
- Инструменты и сервисы для LSI-копирайтинга
4 тактики подбора ключевых слов, которыми не все пользуются
Перевели и адаптировали статью «Advanced Keyword Research: Four Tactics You’re (Probably) Not Using» с нестандартными способами сбора ключей, основанными на практическом опыте.
Около года назад автору статьи пришли несколько идей, как еще можно собирать ключевые слова для продвижения. Он протестировал способы с бесплатными инструментами и получил интересные результаты. Тогда он расширил масштабы тестирования и по итогу вывел четыре способа, которые помогут собрать дополнительные ключи и продвинуть свои статьи в топ.
В статье:
- Подбор ключевиков по молодым сайтам из топа
- Сбор ключей с помощью пользовательского поиска Google (Google Custom Search Engine)
- Тактика моделирования запросов, по которым другие сайты попали в топ за несколько недель
- Реверс-инжиниринг «слабых» сайтов не из топа
Анализируем топ выдачи, чтобы пробиться в лидеры
Стремимся в лидеры выдачи: как анализ статей из топа поможет в работе над контентом, по каким критериям проводить анализ и как сделать это быстрее и эффективнее.
Сложно отслеживать результаты ведения блога и публикации других текстов на сайте без детальной аналитики. Как понять, почему статьи конкурентов в топе, а ваши нет, хотя вы пишете лучше и талантливее?
В статье:
- Что обычно советуют
- Как проводить анализ
- Минусы подхода
- Преимущества анализа контента
- Инструменты
Группировка в таблице связок Yagla
Чтобы сгруппировать фразы, выделите чек-бокс напротив нужных фраз, затем нажмите «Сгруппировать».
* все скриншоты кликабельные – жмите, чтобы увеличить изображение
Рядом с кнопками «Сгруппировать» и «Разгруппировать» будет указано, сколько чек-боксов вы выбрали. Вы всегда знаете, сколько фраз будет сгруппировано или разгруппировано, без необходимости пересчитывать их вручную.
Это позволяет не пропустить нужные фразы и не прихватить лишние в процессе группировки.
Визуально отличить одну группу от другой просто, так как они выделяются разными оттенками цвета:
Итак, механика группировки простая: когда вы выделяете фразы и нажимаете «Сгруппировать», они образуют отдельную группу:
Чтобы к готовой группе присоединить еще ключевые фразы, выделите эту группу целиком, затем – ключи, которые хотите дополнительно добавить, и нажмите «Сгруппировать»:
Чек-бокс прямо в шапке группировки позволяет быстро выделить все ключевые фразы:
Обратите внимание: эффект достигается не за счет «тупой» подмены «запрос = заголовок», а благодаря человекопонятному ценностному предложению для каждой группы запросов, то есть для каждой потребности. Также группировка необходима для оптимизации A/B тестов
Оставлять отдельные фразы (особенно низкочастотные) ни к чему, поскольку на низком трафике тест затянется намного дольше. Чем больше группа, тем больше по ней будет трафика и быстрее завершится тест
Также группировка необходима для оптимизации A/B тестов. Оставлять отдельные фразы (особенно низкочастотные) ни к чему, поскольку на низком трафике тест затянется намного дольше. Чем больше группа, тем больше по ней будет трафика и быстрее завершится тест.
Важно! После группировки фраз в рекламной кампании всё остается без изменений. Группы объявлений как работали, так и продолжают работать
Фильтрация
Чтобы группировать ключевые фразы было удобнее, используйте поиск по ключевой фразе. С помощью него можно быстро отобразить на странице все фразы с нужным значением или словом. Рассмотрим на примере.
Заходим в «Фильтр и сортировка»:
В строке поиска пишем «Срочно» и нажимаем «Отобразить»:
Теперь все ключевые фразы со значением «Срочно» можно в пару кликов объединить в одну группу:
Это очень удобно, так как нам не пришлось искать все эти фразы на странице по отдельности.
Очистить фильтр можно нажатием на крестик около надписи «Выбран 1 фильтр»:
Обратите внимание на следующие нюансы:
1) Если вы группируете две фразы или группы фраз, и у них уже прописаны по одному варианту подменяемых элементов (Вариант B), у полученной новой группы, будет два варианта подмен (Вариант B от первой группы и Вариант C от второй группы), и показываться они будут для этой группы поочередно.
Учитывайте это и при необходимости своевременно убирайте лишние варианты.
2) Если вы отделяете фразы от большой группы, в которой прописан текст к подменяемым элементам, текст остается у той группы, где ключевых фраз больше. Для группы, которая получается пустой (без текста) придется заново прописать подмены.
Генерация рекламных текстов для групп объявлений
Когда мы подготовили документ со структурой, время писать тексты. Мы по умолчанию генерим варианты текстов объявлений под Google и Яндекс, они будут находиться на отдельных вкладках в XLSX-файле с результатом.
-
Переходим в сервис «Генерации текстов», выбираем файл, нажимаем «Отправить в Пекло».
Вы попадете на блок настройки генерации рекламных текстов:
-
Выбираем количество текстов на группу объявлений. Минимально рекомендуем добавлять два варианта, чтобы Google Ads и Яндекс.Директ могли тестировать разные версии объявлений внутри одной группы и выбирать лучшую. Это необходимо для качественной рекламной кампании.
-
Изучите детальные настройки. По умолчанию заданы логичные настройки, однако вы можете настраивать инструмент под себя.
Всегда и по умолчанию для Заголовка 1 в тексте объявлений используется ваше ключевое слово. Это необходимо для получения высокого CTR.
Также существует поверье, что если в заголовке каждое слово писать с заглавной буквы, то CTR будет выше — тестируйте.
Есть несколько вариантов, как поступать, если ваше ключевое слово не помещается в Заголовок 1. Мы советуем переносить ваш ключ в Заголовок 2 (если фраза заканчивается «… в Москве», то перенос будет вместе с предлогом) и позже уже вручную допиливать тексты объявлений по ситуации.
Если вы указываете частотность ключевых слов, то для Заголовка 1 алгоритм подберет самое высокочастотное слово. Как правило, они самые корректные и без ошибок. Так, тексты сгенерируются качественнее.
-
Настраиваем Заголовок 2. Логика простая: сколько текстов на группу объявлений вы настраиваете, столько вторых заголовков и задавайте. Здесь можно отобразить либо самое сильное УТП, либо бренд или слоган компании.
-
Настраиваем Заголовок 3 для Google Ads. Так как Заголовок 3 не всегда отображается, вводите сюда менее важные варианты текстов — смысл объявления не должен теряться, если этот заголовок не покажется.
-
Настраиваем Описания для текстов объявлений. Это важный момент в создании текстов объявлений. Лучше задать 7–9 вариантов УТП. Чем больше вариантов разной длины, тем лучше наш алгоритм сможет их сочетать и адаптировать под ограничения рекламных систем по символам.
Не указывайте 2–4 варианта УТП с длиной ≈80 символов: система не сможет их комбинировать и сгенерировать тексты. Если у вас есть готовое описание, лучше вставьте его в финальном документе в Excel.
-
Добавьте варианты призывов к действию. Основа Описания для объявлений — это предыдущий блок с УТП. Призывы к действию добавляются в конце объявления после УТП. Добавляйте несколько вариантов разной длины. Но именно призывы к действию рекомендуем делать максимально краткими.
-
Задаем URL сайта. Здесь просто вставляйте ссылку, которая будет вести на главную страницу.
В будущем мы планируем сделать инструмент для автоматической настройки отображаемых URL и для подбора финальных URL, если у вас многостраничный сайт. Благодаря этому разные группы объявлений будут вести на разные страницы.
-
Отправляем в Peklo и смотрим на результат.
Результат будет выглядеть примерно так:
На листе PekloTool Data будут собраны все введенные тексты для заголовков, описания, призывы и т. д. На отдельных листах — Google и Yandex — тексты, соответствующим требованиям рекламных систем.
Что нужно сделать, чтобы доработать получившиеся тексты:
-
Найти слова на кириллице и заменить их написание латиницей. Например, найти «бмв» и заменить на BMW.
-
Если часть ключевого слова попала в Заголовок 2 и он получился коротким, можно через формулу =ячейка&» добавочный текст» дополнить этот заголовок и протянуть по всем таким заголовкам. Пример:
-
Текст в Заголовках 1, которые не выглядят привлекательно, заменить на дефолтный текст или отредактировать.
После доработок рекламная кампания будет готова к загрузке в аккаунты. Для этого понадобятся программы Google Ads Editor и Директ Коммандер.
Распределение запросов по страницам сайта
Этот этап тесно пересекается с группировкой запросов и зачастую осуществляется одновременно с ним. Но всё же разберу его, чтобы не оставлять места неясностям. Опять же, предложу три варианта: Key Collector (я себя чувствую уже тайным менеджером по продажам), Seopult и руки, которые из плеч растут, а не сервис. Первые два варианта годятся для уже существующего и проиндексированного сайта, а третий, понятное дело, универсален 🙂
Распределение семантического ядра через Key Collector
Как говорит В.В. Путин, буду краток. В проекте Key Collector запускаем анализ релевантных страницы в ПС Яндекс для вашего сайта:
Сортируем полученный столбец путем клика по нему. Получаем группы запросов, объединенных общей релевантной страницей по мнению Яндекса.
Распределение запросов по страницам через Seopult
Никто не отрицает того факта, что ссылочные агрегаторы обладают полезным инструментарием, которым мы и будем пользоваться, благо что бесплатно. В данном случае обратимся к системе Seopult. Технология тут та же самая, что и в первом варианте. Создаем проект, добавляем запросы и определяем для них страницы для продвижения. Экспортируем полученные данные в Excel и всё.
Очистка семантики от мусора и поиск минус-слов
Это отдельный инструмент, который помогает очистить первичный список ключевых слов и сразу получить список минус-слов для рекламной кампании.
Внимание: инструмент работает только для зарегистрированных пользователей. Он простой и быстрый:
Он простой и быстрый:
-
Вставляем весь список ключевых слов и нажимаем «Начать работу».
-
У вас появляется рабочая область, где вы, кликая по нерелевантным словам, выделяете все фразы с ними, слева автоматически будет создаваться список минус-слов.
-
После нажатия на кнопку «Получить список рабочих слов» система выведет все слова за исключением тех, что содержат в себе минус-слова.
В итоге вы можете быстро очистить свои ключевые слова от мусора, скопировать очищенный список в рабочий документ и перейти к группировке ключевых слов. А собранные минус-слова позже добавить в качестве минус-слов на уровне кампании, группы объявлений или аккаунта.
Также есть удобная функция «Найти словоформы выбранных слов». C ее помощью в загруженной семантике можно найти выбранные минус-слова в других падежах, множественном и единственном числах
Для Google Ads важно прописывать минус-слова во всех числах и склонениях
Способы составления семантического ядра
Key Collector
Для составления семантики мы можем воспользоваться программами для создания СЯ. Какие-то из них делают почти всю работу за вас – их еще называют автоматическими. В каких-то сервисах придется больше работать самостоятельно.
Например, есть такая платная утилита Key Collector. Хотя в ней этот процесс почти полностью автоматизирован, необходимо знать, как настроить Key Collector. На выходе вам лишь остается немного прибраться в запросах, убрав оттуда наиболее бесполезные, что включает в себя запросы от роботов, спам и т. д. Стоимость такой программы составляет почти 2 000 рублей.
Яндекс Вордстат
Заниматься сбором семантики можно и с помощью сервиса от Яндекса – Вордстат. Им очень легко пользоваться, достаточно просто ввести ключевое слово, он выведет вам запросы, в которых присутствует данный ключ. Вместе с этим Wordstat покажет вам и похожие запросы, которые также могут быть интересны при продвижении.
В этой статье с помощью Вордстата мы будем собирать первичные ключи, которые понадобятся нам для дальнейшего сбора семантического ядра. Но об этом позже, а пока я приведу вам еще несколько способов, с помощью которых можно собрать семантику.
Яндекс Вордстат + СловоЁБ
Программа с таким красочным названием является абсолютно бесплатным аналогом Key Collector. Естественно и функционала в нем чуть меньше, чем в коммерческом конкуренте, но для сбора семантического ядра под поисковое продвижение этого вполне хватит.
Если вам интересно, чем СловоЁБ отличается от Кей Коллектора, просто взгляните на эту табличку.
Безусловно, отличий здесь вагон и маленькая тележка. Однако для простого сбора ядра возможностей СловоЁБа вполне хватит.
Онлайн-сервисы
Итак, помимо вышеописанных вариантов, семантику можно сделать с помощью онлайн-сервисов. Если вы забьете запрос “Сбор семантики онлайн”, то поисковик выдаст вам большое количество всевозможных онлайн-инструментов. Они могут быть как хорошими, так и плохими. И, соответственно, как платными, так и бесплатными.
С помощью различных онлайн-сервисов можно еще узнать семантическое ядро конкурентов. Будьте уверены, что практически все компании занимаются проверкой данных своих потенциальных соперников.
Заказ у специалиста
Вы можете просто купить готовое решение у специалиста. Он все сделает, и на выходе вы получите целостный файлик со всеми запросами. Далее из него уже можно будет создать список статей с техническими заданиями к ним. Ну и отдать это все на растерзание копирайтерам. Но это уже вопрос делегирования обязанностей, его сегодня затрагивать мы не будем.
Как группировали раньше
Раньше SEO-специалисты группировали запросы вручную «на глаз», объединяя их в группы на основании семантической схожести. Приведу гипотетический пример с недвижимостью. Так, в одну группу попадали запросы «снять квартиру», «сколько стоит снять квартиру» и «снять однокомнатную квартиру».
Как правило, при группировке не учитывались запросы с одним и тем же интентом (пользовательским намерением), отличающиеся по семантике. По этой причине в кластер с ключевым словом «снять квартиру» ключевое слово «аренда квартир» часто не попадало.
Если верить некоторым источникам, количество ошибочных распределений при таком способе доходило до тридцати процентов, что снижало скорость и эффективность продвижения.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.