Как извлечь картинки из файла pdf
Содержание:
- Какую выбрать тематику канала?
- Как в PDF добавить страницу из другого PDF
- Как конвертировать pdf в jpg
- 11 неизвестных, но нужных фишек WhatsApp
- Через Adobe Reader или Foxit Reader
- Как в PDF распечатать 2 страницы на одном листе
- Как вытащить изображение из PDF (3 способ)
- Видео
- Вставка текстового содержимого копированием
- Извлечение изображений из PDF
- Что такое оптимизация на Андроид
- Как вытащить изображение из PDF (3 способ)
- SmallPDF
- 2 простых способа копирования текста из PDF
- 3. Как вставить PDF в Word как объект
- Копируем текст из PDF файла в Word с помощью онлайн конвертеров
- Экспорт текста через pdf2txt.py
Какую выбрать тематику канала?
Сразу нужно сказать, что просто за просмотры размещенного на вашем канале материала платить никто не будет. Возможность заработать всегда сводится к рекламодателям. Заинтересовать их и привлечь к сотрудничеству можно в том случае, если ваш видеоканал имеет постоянных подписчиков и регулярно набирает пусть и не самое большое количество просмотров на «Ютубе», но по крайней мере необходимое для сотрудничества. Ролики должны быть полезными, интересными и оригинальными.
Темы рассчитаны на разные слои и группы населения:
- финансы и экономика;
- детские развлекательные программы;
- юмористические каналы;
- автомобили;
- фильмы и обзоры новинок кинематографа;
- спорт и еще многое другое.
Самые популярные просмотры в «Ютубе» – это, как правило, юмористические и музыкальные ролики, но это не означает, что они самые рентабельные.
Не стоит забывать о законодательстве, регулирующем сферу защиты авторских прав. Внимательно ознакомьтесь с ним прежде, чем приступить к созданию канала.
Как в PDF добавить страницу из другого PDF
С помощью данной опции возможно объединить файлы любого формата, включая Word, Excel, PowerPoint:
В «Инструментах» выбрать пункт «Объединить…».
Перетащить файл прямо в интерфейс программы.
Документы отобразятся на экране.
Если нужно отсортировать страницы, двойным щелчком левой кнопки мышки развернуть документ и путем перетаскивания поменять местами листы.
Для удаления конкретной страницы следует навести на нее курсор и нажать на появившийся значок корзины справа.
После внесенных изменений двойным кликом по первому листу выйти из режима просмотра. Нажать на кнопку «Объединить». Запустится процесс преобразования, который займет несколько секунд (в зависимости от объема).
Для добавления страницы необходимо провести некоторые манипуляции:
- Открыть файл, из которого должен быть изъят один лист.
- Двойным щелчком открыть левую вертикальную панель инструментов.
- Выбрать миниатюры – первый значок.
Вызвать параметры, кликнув на соответствующий значок (расположен возле корзины).
Выбрать опцию «Извлечь…». Указать номер листа, который следует извлечь. Отметить галочкой пункт об изъятии в отдельный файл. Нажать «Ок».
- Закрыть данный файл.
- Открыть документ, в который будет добавлен один лист. Повторить действия из п.2-4.
- Перейти по пути «Вставить страницы» – «Из файла».
- В открывшейся папке выбрать файл.
- Задать настройки, куда будет вставлен новый лист.
Опция доступна только в платной версии программы Acrobat Pro DC.
Как конвертировать pdf в jpg
Есть много способов, чтобы переформатировать pdf в jpg, но не все из них выгодны и удобны. Некоторые и вовсе абсурдные, что о них даже слышать никому не стоит. Рассмотрим два самых популярных способа, которые помогут сделать из файла pdf набор изображений в формате jpg.
Способ 1: использование онлайн конвертера
- После того, как сайт загрузился, можно добавлять в систему нужный нам файл. Сделать это можно двумя способами: нажать на кнопку «Выбрать файл» или перенести сам документ в окно браузера в соответствующую область.
Перед конвертацией можно изменить некоторые настройки, чтобы полученные в итоге документы jpg были качественными и читаемыми. Для этого пользователю представлена возможность изменить цвета графических документов, разрешение и формат изображений.
После загрузки документа pdf на сайт и настройки всех параметров можно нажимать на кнопку «Конвертировать». Процесс займет некоторое время, поэтому придется немного подождать.
Как только процесс конвертации завершится система сама откроет окно, в котором необходимо будет выбрать место для сохранения полученных файлов jpg (сохраняются они в одном архиве). Теперь осталось только нажать на кнопку «Сохранить» и пользоваться изображениями, полученными из документа pdf.
Способ 2: использование конвертера для документов на компьютере
- Как только программа установлена на компьютер, можно приступать к конвертации. Для этого надо открыть документ, который необходимо преобразовать из формата pdf в jpg. Рекомендуется работать с документами pdf через программу Adobe Reader DC.
- Теперь следует нажать на кнопку «Файл» и выбрать пункт «Печать…».
Следующим шагом надо выбрать виртуальный принтер, который будет использоваться для печати, так как нам не надо непосредственно распечатать сам файл, надо лишь получить его в другом формате. Виртуальный принтер должен называться «Universal Document Converter».
Выбрав принтер, необходимо нажать на пункт меню «Свойства» и убедиться, что сохраняться документ будет в формате jpg (jpeg). Кроме этого можно настроить много разных параметров, которые невозможно было изменить в онлайн-конвертере. После всех изменений можно нажимать на кнопку «Ок».
Нажатием на кнопку «Печать» пользователь начнет процесс преобразования документа pdf в изображения. После его завершения появится окно, в котором опять придется выбрать место сохранения, название полученного файла.
Вот такие два хороших способа являются наиболее удобными и надежными в работе с pdf файлами. Перевести данными вариантами документ из одного формата в другой довольно просто и быстро. Выбирать какой из них лучше следует только пользователю, ведь у кого-то могут возникнуть проблемы с подключением к сайту загрузки конвертера для компьютера, а у кого-то могут появиться и другие проблемы.
Если вы знаете какие-то еще способы конвертирования, которые будут простыми и не затратными по времени, то пишите их в комментарии, чтобы и мы узнали, о вашем интересном решении такой задачи как конвертирование документа pdf в jpg формат.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
11 неизвестных, но нужных фишек WhatsApp
Через Adobe Reader или Foxit Reader
Если у вас старая версия MS Word, но зато есть программа Adobe Acrobat Reader или Foxit Reader (в одной из них обычно и открываются все pdf файлы), тогда конвертировать можно с помощью нее.
1. Открываем файл в Adobe Reader или Foxit Reader и копируем нужный фрагмент документа.
Обычно достаточно просто открыть файл и он сразу же запустится в одной из этих программ (вверху будет написано, в какой именно).
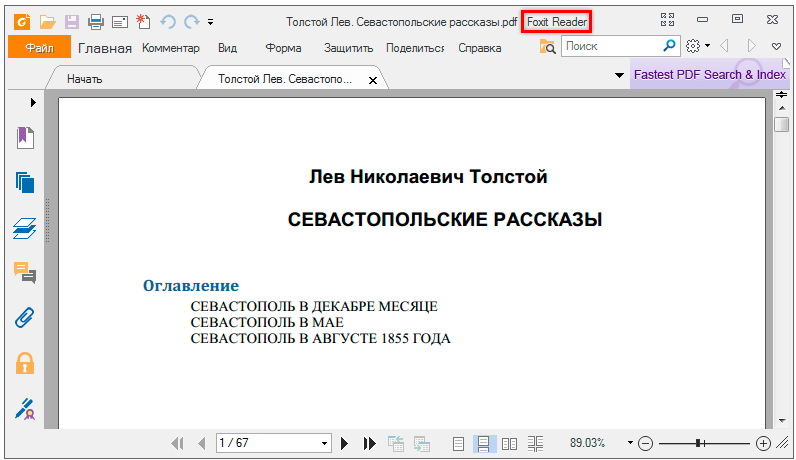
Для копирования всего текста в Adobe Reader нажимаем вверху на «Редактирование» и выбираем «Копировать файл в буфер обмена».

В Foxit Reader для переноса всего текста нужно нажать на «Главная» вверху, щелкнуть по иконке буфера обмена и выбрать «Выделить все». Затем опять щелкнуть по иконке и выбирать «Копировать».
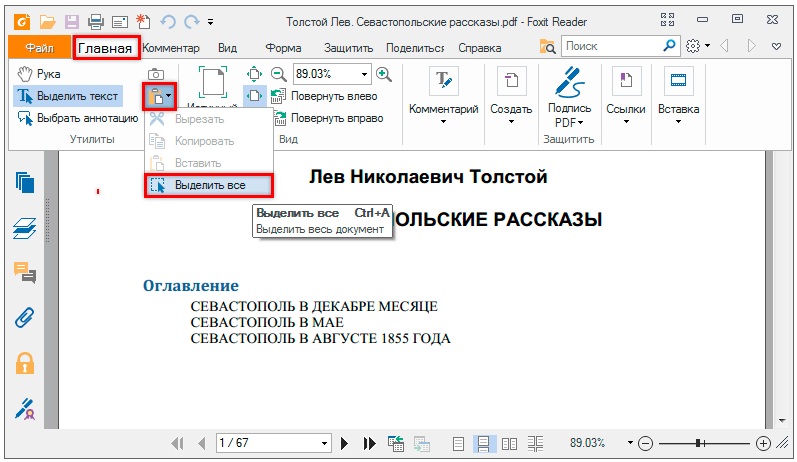
2. Создаем документ в Ворде. Для этого щелкаем на свободном любом месте Рабочего стола правой кнопкой мыши и выбираем пункт Создать → Документ Microsoft Office Word.
А можно просто открыть программу через Пуск → Все программы → Microsoft Office → Microsoft Office Word.
3. Вставляем в документ тот фрагмент, который мы скопировали из pdf файла. Для этого щелкаем правой кнопкой мыши по листу и в контекстном меню выбираем пункт «Вставить».

В итоге получаем тот же текст, но с возможностью редактирования. Правда, часто он добавляется с немного измененным форматированием и без изображений.

Минусы
- Если документ большой, вставка происходит очень медленно или Ворд просто намертво виснет. А, бывает, даже небольшой текст не вставляется. Выход: выделять/копировать/вставлять по частям.
- Не копируются изображения. Выход: делать их скриншоты, нажав на клавишу клавиатуры Print Screen, после чего вставлять в Ворд (правая кнопка – Вставить). Но придется еще обрезать и менять размер полученной картинки.
- Иногда форматирование страдает очень сильно: шрифты, размер букв, цвета и т. д. Выход: править текст вручную.
Резюме: с обычным текстом такой вариант вполне допустим, но если в документе есть еще и таблицы, списки, изображения, лучше конвертировать другими способами.
Как в PDF распечатать 2 страницы на одном листе
Данная опция также называется n-up. Кроме непосредственной печати на одном листе нескольких страниц позволяет их упорядочивать горизонтально или вертикально.
Для этого после открытия документа в приложении необходимо:
На верхней панели инструментов вызвать меню «Файл» – «Печать». Или воспользоваться комбинацией клавиш Ctrl+P.
Откроется новое окно. В пункте настройки размера и обработки страниц кликнуть по варианту «Несколько».
Указать количество страниц на листе (2, 4, 6, 9, 16) или задать свое значение.
В следующем пункте указать порядок страниц (горизонтально – в ряд слева направо; горизонтально в обратном порядке; вертикально – с левого верхнего угла, сверху вниз, слева направо; вертикально в обратном порядке).
- Выбрать ориентацию и задать другие настройки (добавить рамку и т.д.).
- Нажать «Печать» (или «Ок»).
Опция доступна в бесплатной версии программы Adobe Acrobat Reader DC.
Как вытащить изображение из PDF (3 способ)
В некоторых случаях, у пользователей возникают затруднения, когда они пытаются вытащить картинку из PDF первыми двумя способами, а ничего не получается.
Файл в формате PDF может быть защищен. Поэтому, извлечь картинки из PDF файла такими способами не удается.
В некоторых ситуациях, необходимо скопировать картинку из PDF, которая не имеет четких прямоугольных границ. Давайте усложним задачу. Как быть, если из защищенного PDF файла нужно скопировать изображение, не имеющее четких границ (обрамленное текстом или другими элементами дизайна)?
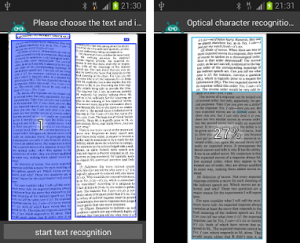
Можно очень легко обойти эти препятствия. Решение очень простое: необходимо воспользоваться программой для создания снимков экрана. Потребуется всего лишь сделать скриншот (снимок экрана) необходимой области, которую входит интересующее нас изображение.
Откройте PDF файл в программе Adobe Acrobat Reader. Затем запустите программу для создания скриншотов. Для этого подойдет стандартная программа «Ножницы», входящая в состав операционной системы Windows, или другая подобная более продвинутая программа.
Я открыл в Adobe Reader электронную книгу в формате PDF, которая имеет защиту. Я хочу скопировать изображение, которое не имеет четких прямоугольных границ.
Для создания снимка экрана, я использую бесплатную программу PicPick (можно использовать встроенное в Windows приложение Ножницы). В программе для создания скриншотов, нужно выбрать настройку «Захват произвольной области».
Далее с помощью курсора мыши аккуратно обведите нужную картинку в окне программы, в данном случае, Adobe Acrobat Reader.
Вам также может быть интересно:
- Как сохранить картинки из Word
- Как сохранить файл в PDF — 3 способа
После захвата изображения произвольной области, картинка откроется в окне программы для создания скриншотов. Теперь изображение можно сохранить в необходимый графический формат на компьютере. В настройках приложения выберите сохранение картинки в соответствующем формате.
Видео
Вставка текстового содержимого копированием
Здесь необходимо любым известным вам способом скопировать текст из пдф файла и вставить его в документ Word. Можно скопировать фрагмент или все сразу (CTRL+A). При вставке содержимого выбирайте команду Сохранить исходное форматирование
.
Это простые способы вставки содержимого пдф, которые требуют некоторого усилия для приведения текста в нормальный вид. Но в интернете вы можете найти сервисы по преобразованию pdf в Word. Но они не всегда дают ожидаемый результат, и правка форматирования возможно у вас отнимет не меньше времени, чем описанный выше способ. Или же установить на компьютер специальную программу распознавания, которую еще нужно будет освоить. Ну, если вам не срочно, то можно и так. Пробуйте и решайте, что удобнее для вас.
Решение проблемы
Если вы обладатель , то при открытии документ PDF в них будет автоматически преобразован в редактируемый формат. Ставьте последние версии Word.
Извлечение изображений из PDF
К сожалению, не существует пакетов Python, которые выполняют извлечение изображений из PDF. Наиболее близкий проект, который я нашел – это minecart, который может делать это, но он работает только на Python 2.7. У меня не вышло его запустить при работе с примером PDF, который у меня был. Однако есть способ, который позволяет извлекать JPG из PDF. Вот пример кода:
Python
# Извлечение jpg из pdf. Быстро и дерзко:
import sys
pdf = file(sys.argv, «rb»).read()
startmark = «\xff\xd8»
startfix = 0
endmark = «\xff\xd9»
endfix = 2
i = 0
njpg = 0
while True:
istream = pdf.find(«stream», i)
if istream < 0:
break
istart = pdf.find(startmark, istream, istream+20)
if istart < 0:
i = istream+20
continue
iend = pdf.find(«endstream», istart)
if iend < 0:
raise Exception(«Didn’t find end of stream!»)
iend = pdf.find(endmark, iend-20)
if iend < 0:
raise Exception(«Didn’t find end of JPG!»)
istart += startfix
iend += endfix
print(«JPG %d from %d to %d» % (njpg, istart, iend))
jpg = pdf
jpgfile = file(«jpg%d.jpg» % njpg, «wb»)
jpgfile.write(jpg)
jpgfile.close()
njpg += 1
i = iend
|
1 |
# Извлечение jpg из pdf. Быстро и дерзко: importsys pdf=file(sys.argv1,»rb»).read() startmark=»\xff\xd8″ startfix= endmark=»\xff\xd9″ endfix=2 i= njpg= whileTrue istream=pdf.find(«stream»,i) ifistream< break istart=pdf.find(startmark,istream,istream+20) ifistart< i=istream+20 continue iend=pdf.find(«endstream»,istart) ifiend< raiseException(«Didn’t find end of stream!») iend=pdf.find(endmark,iend-20) ifiend< raiseException(«Didn’t find end of JPG!») istart+=startfix iend+=endfix print(«JPG %d from %d to %d»%(njpg,istart,iend)) jpg=pdfistartiend jpgfile=file(«jpg%d.jpg»%njpg,»wb») jpgfile.write(jpg) jpgfile.close() njpg+=1 i=iend |
Это также работает для тех файлов PDF, которые я использую. В StackOverflow есть вариации этого кода, некоторые из которых используют PyPDF2 различными способами. Однако в моем случае они не помогли.
Я рекомендую использовать инструмент Poppler для извлечения изображений. Poppler включает в себя инструмент под названием pdfimages, который вы можете использовать с модулем Python под названием subprocess. Вот как использовать его без Python:
Shell
pdfimages -all reportlab-sample.pdf images/prefix-jpg
| 1 | pdfimages-all reportlab-sample.pdfimagesprefix-jpg |
Убедитесь в том, что папка с изображениями (или папку любой другой выдачи, которую вы хотите создать) уже создана, так как pdfimages не сделает это за вас.
Давайте напишем скрипт Python, который выполняет эту команду, и убедимся, что папка выдачи также существует:
image_exporter.py
Python
# image_exporter.py
import os
import subprocess
def image_exporter(pdf_path, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cmd = [‘pdfimages’, ‘-all’, pdf_path,
‘{}/prefix’.format(output_dir)]
subprocess.call(cmd)
print(‘Images extracted:’)
print(os.listdir(output_dir))
if __name__ == ‘__main__’:
pdf_path = ‘reportlab-sample.pdf’
image_exporter(pdf_path, output_dir=’images’)
|
1 |
# image_exporter.py importos importsubprocess defimage_exporter(pdf_path,output_dir) ifnotos.path.exists(output_dir) os.makedirs(output_dir) cmd=’pdfimages’,’-all’,pdf_path, ‘{}/prefix’.format(output_dir) subprocess.call(cmd) print(‘Images extracted:’) print(os.listdir(output_dir)) if__name__==’__main__’ pdf_path=’reportlab-sample.pdf’ image_exporter(pdf_path,output_dir=’images’) |
В этом примере мы импортировали модули subprocess и os. Если папка выдачи не существует, мы попытаемся создать её. Далее мы используем метод вызова subprocess для запуска pdfimages. Мы используем вызов, так как он будет ожидать pdfimages, пока тот закончит работу. Вы можете использовать Popen вместо этого, но это фактически запускает процесс в фоновом режиме. Наконец, мы выводим список папки выдачи для подтверждения того, что изображения были добавлены в неё.
Есть статьи, которые ссылаются на библиотеку под названием Wand, которую вы тоже можете попробовать. Это оболочка ImageMagick
Также обратите внимание на то, что существует связка Python с Poppler под названием pypoppler, однако я не нашел примеров того, что этот пакет выполняет извлечение изображений
Что такое оптимизация на Андроид
Как вытащить изображение из PDF (3 способ)
В некоторых случаях, у пользователей возникают затруднения, когда они пытаются вытащить картинку из PDF первыми двумя способами, а ничего не получается.
Файл в формате PDF может быть защищен. Поэтому, извлечь картинки из PDF файла такими способами не удается.
В некоторых случаях, необходимо скопировать картинку из PDF, которая не имеет четких прямоугольных границ. Давайте усложним задачу. Как быть, если из защищенного PDF файла нужно скопировать изображение, не имеющее четких границ (обрамленное текстом или другими элементами дизайна)?
Можно очень легко обойти эти препятствия. Решение очень простое: необходимо воспользоваться программой для создания снимков экрана. Потребуется всего лишь сделать скриншот (снимок экрана) необходимой области, которую входит интересующее нас изображение.
Откройте PDF файл в программе Adobe Acrobat Reader. Затем запустите программу для создания скриншотов. Для этого подойдет стандартная программа «Ножницы», входящая в состав операционной системы Windows, или другая подобная более продвинутая программа.
Я открыл в Adobe Reader электронную книгу в формате PDF, которая имеет защиту. Я хочу скопировать изображение, которое не имеет четких прямоугольных границ.
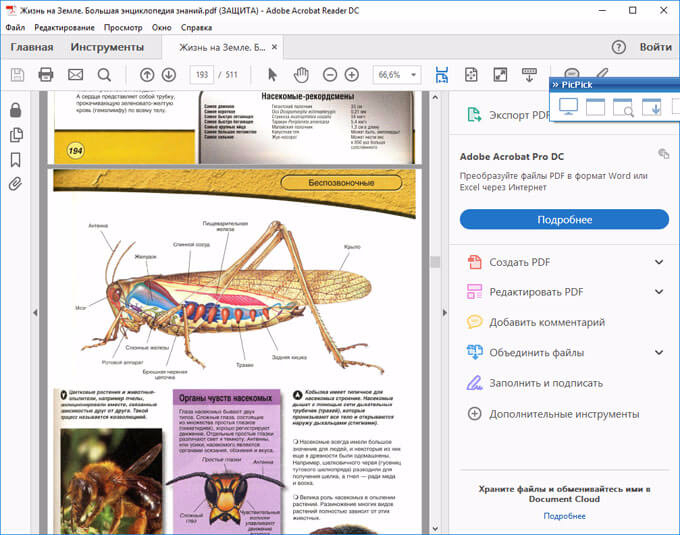
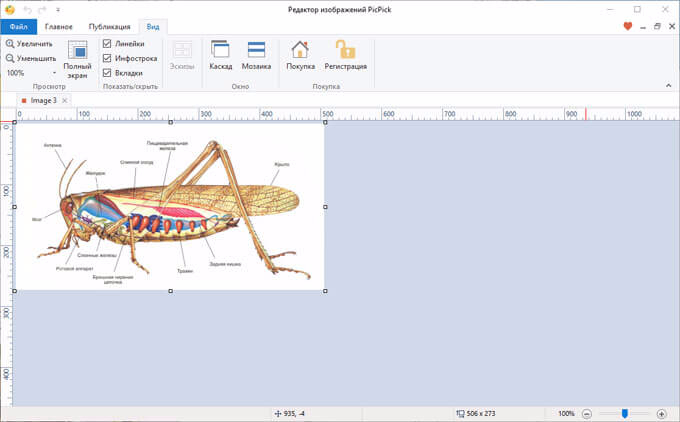
Для создания снимка экрана, я использую бесплатную программу PicPick (можно использовать встроенное в Windows приложение Ножницы). В программе для создания скриншотов, нужно выбрать настройку «Захват произвольной области».
Далее с помощью курсора мыши аккуратно обведите нужную картинку в окне программы, в данном случае, Adobe Acrobat Reader.
После захвата изображения произвольной области, картинка откроется в окне программы для создания скриншотов. Теперь изображение можно сохранить в необходимый графический формат на компьютере. В настройках приложения выберите сохранение картинки в соответствующем формате.
SmallPDF
Веб-сервис SmallPDF, понравился мне больше, чем предыдущий. Та же самая схема была обработана примерно в 2 раза быстрее и загрузилась обратно в считанные секунды. Структура документа, как и в первом случае, сохранилась неизменной, но искажений в нем стало меньше.
Перейти на Smallpdf
Пользоваться SmallPDF тоже очень просто:
- Загружаем или перетаскиваем на выделенное поле ПДФ-файл. Кстати, сервис поддерживает загрузку документов из Dropbox и Google Drive.
- Нажимаем «Конвертировать».
- Скачиваем результат на компьютер либо сохраняем его в своем Dropbox или Google Drive.
Из недостатков SmallPDF стоит отметить лишь два. Первый – это ограничение бесплатной версии двумя загрузками в час (безлимитное использование по подписке стоит $4-6 в месяц). Второй – сохранение результата только в формате DOCX.
2 простых способа копирования текста из PDF

2020-08-06 12:53:21 • Отправлено в: Практическое руководство • Проверенные решения
PDF — это самый простой и безопасный способ отправки и получения важного содержимого.Так можем ли мы скопировать текст из PDF ? С PDFelement мы можем сделать это эффективно
4 шага для копирования текста из PDF
Прежде чем продолжить, убедитесь, что вы скачали последнюю версию PDFelement. После завершения загрузки выполните простой процесс установки, который займет всего несколько секунд. Тогда вы готовы научиться копировать текст из PDF.
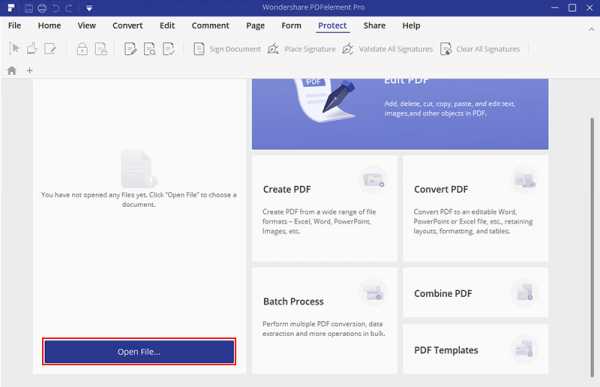
Шаг 1. Загрузите PDF
Теперь запустите недавно установленный PDFelement и откройте документ PDF, который вы хотите скопировать.На вкладке «Главная» нажмите кнопку «Открыть файл». Теперь выберите файл PDF, из которого вы хотите скопировать текст, и снова нажмите кнопку «Открыть».
Шаг 2. Скопируйте текст из PDF
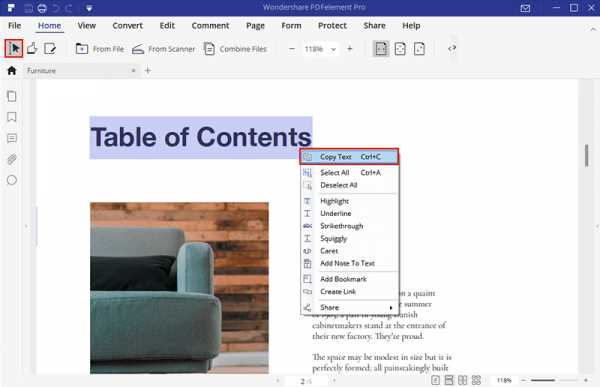
Если ваш PDF-файл можно выбрать, то вы можете нажать кнопку «Выбрать» и щелкнуть мышью, чтобы выбрать нужный текст, а затем скопировать текст из PDF с помощью следующих советов и вставить в целевой документ.
- Щелкните текст правой кнопкой мыши и выберите «Копировать текст»
- Нажмите «Ctrl + C» после выделения текста
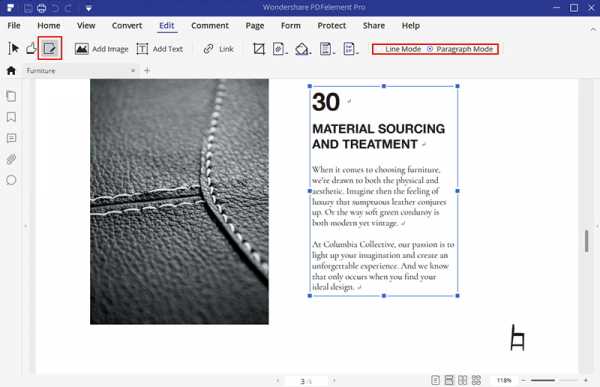
Шаг 3.Отредактируйте свой PDF-файл (необязательно)
Использование режима редактирования также может помочь вам скопировать текст из PDF. Нажмите кнопку «Редактировать», чтобы включить режим редактирования, и вы можете выбрать для редактирования «Режим строки» или «Режим абзаца». Выделите текст, который вам нужно скопировать из PDF.
Шаг 4. Сохраните файл PDF
После копирования текста из файла PDF сохраните файл перед его закрытием. Щелкните вкладку «Файл» в верхнем левом углу и выберите кнопку «Сохранить» или «Сохранить как». Теперь дайте файлу PDF имя и сохраните его на своем компьютере.
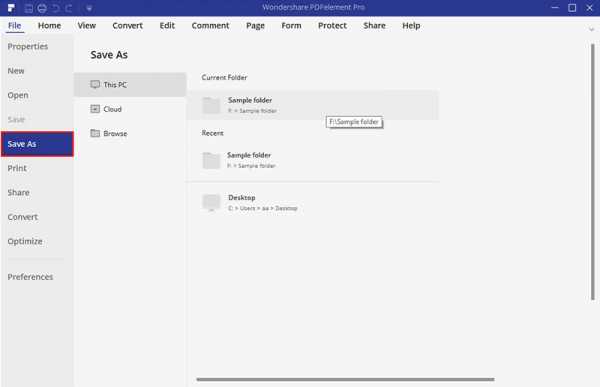
Как скопировать текст из PDF
Есть еще один способ скопировать текст из PDF с помощью PDFelement — напрямую преобразовать PDF в документ другого формата.
После открытия PDFelement нажмите кнопку «Открыть файл …», чтобы выбрать документ PDF для открытия.
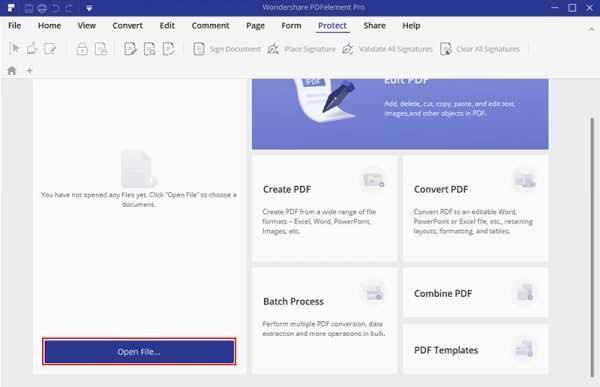
Шаг 2. Скопируйте текст из PDF в Word
Нажмите кнопку «Преобразовать»> «В Word», чтобы начать преобразование. Вот как скопировать текст из PDF в Word.А если вы хотите скопировать текст из PDF в Excel, вы можете нажать кнопку «В Excel», чтобы сделать это напрямую.
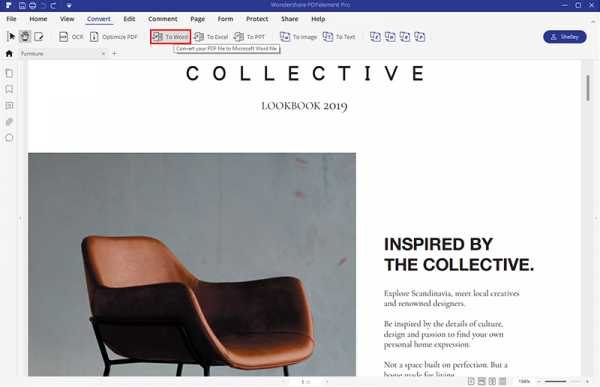
Советы: почему нельзя скопировать текст из PDF
Если ваш PDF-файл не может быть выбран, например, защищенный PDF-файл или отсканированный PDF-файл, то фактически вы не можете скопировать текст из PDF. В этом случае PDFelement может помочь вам скопировать текст из PDF с некоторыми дополнительными шагами. Поэтому, если ваш PDF-файл является файлом, защищенным паролем, обратитесь к этой статье о том, как скопировать текст из защищенного PDF-файла.Если ваш PDF-файл представляет собой отсканированный PDF-файл или файл PDF на основе изображений, см. Здесь, как скопировать текст с изображения.
PDFelement позволяет добавлять новый текст, удалять текст или изменять текст в документе. Вы также можете заменить изображения в файле PDF, изменить их размер или настроить их ориентацию. Одна из лучших функций — это встроенный инструмент распознавания текста, который позволяет извлекать текст из отсканированных файлов PDF.
Кроме того, PDFelement позволяет создавать PDF-файлы из различных изображений, пустых страниц, слайдов или форм.Точно так же вы можете преобразовать любой файл PDF в листы Word, PPT, Excel или даже веб-страницы. После того, как вы создали PDF-файл, его также можно защитить паролем для предотвращения несанкционированного доступа и редактирования.
Скачать или купить PDFelement бесплатно прямо сейчас!
Скачать или купить PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
3. Как вставить PDF в Word как объект
Вы можете вставить свой PDF в Word как объект. Это означает, что вы можете легко получить доступ к PDF из вашего документа Word. Кроме того, в зависимости от выбранных параметров PDF-файл может обновляться автоматически.
Для этого откройте Word и перейдите на вкладку « Вставка » на ленте. В разделе « Текст » нажмите « Объект» .
В открывшемся окне перейдите на вкладку « Создать из файла ». Нажмите Обзор … , найдите и выберите свой PDF, затем нажмите Вставить .
На данный момент, вы можете просто нажать кнопку ОК . Это вставит статический захват первой страницы PDF в документ Word. Если дважды щелкнуть этот скан, откроется PDF-файл.
Кроме того, вы можете выбрать ссылку на файл . Хотя при этом по-прежнему вставляется только первая страница PDF, любые изменения, которые происходят в этом PDF, будут автоматически отражаться в документе Word.
Если вы не хотите видеть первую страницу, выберите View as Icon . По умолчанию будет отображаться значок Adobe PDF и название вашего PDF. Вы можете нажать Изменить значок …, если вы хотите отобразить другой значок.
Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
Популярные онлайн конвертеры из PDF в Word.
Когда возникает необходимость извлечь картинку из PDF файла, многие пользователи испытывают трудности. Дело в том, что PDF файлы не так просто редактировать.
Формат PDF (Portable Document Format), разработанный компанией Adobe Systems, широко распространен и используется для хранения документов, инструкций, электронных книг. Преимуществами формата является то, что документ, созданный в формате PDF, одинаково отображается на любом устройстве.
Как из PDF файла вытащить картинки? Для этого, существуют продвинутые платные программы для редактирования PDF файлов. В этой статье мы рассмотрим способы извлечения изображений из PDF, без использования платных инструментов.
Вы познакомитесь с тремя самыми простыми способами для извлечения картинок из PDF. Файл в формате PDF может иметь разные свойства. Поэтому для решения проблемы: извлечения картинки из PDF, мы будем применять разные способы.
Для этого, нам понадобится бесплатная программа Adobe Acrobat Reader — просмотрщик PDF файлов, и приложение для создания скриншотов.
Если вам, наоборот, нужно сделать PDF файл из изображений, прочитайте статью на моем сайте.
Экспорт текста через pdf2txt.py
Инструмент командной строки pdf2txt.py, который идет вместе с PDFMiner может извлекать текст из файла PDF и выводить его на stdout по умолчанию. Он не будет распознавать текст из изображений, а PDFMiner не поддерживает оптическое распознавание символов. Давайте попробуем использовать простейший метод его использования, суть которого заключается в простой передаче пути к нашему PDF файлу. Мы используем наш w9.pdf Открываем терминал и ищем место, где вы сохранили этот файл, или обновляем указанную ниже команду, для наводки на этот файл:
Shell
pdf2txt.py w9.pdf
| 1 | pdf2txt.pyw9.pdf |
Если вы запустите это команду, она выведет весь текст в stdout. Вы также можете сделать так, чтобы pdf2txt.py записывал текст в файл в качестве текста, HTML или XML. Формат XML даст много информации о PDF файле, так как хранит в себе расположение каждой буквы в документе, а также информацию о шрифтах.
HTML не рекомендуется, так как разметка, генерируемая pdf2txt, скорее всего будет выглядеть не очень хорошо. Посмотрим, как получить выдачу в различных форматах:
Shell
pdf2txt.py -o w9.html w9.pdf
pdf2txt.py -o w9.xml w9.pdf
|
1 |
pdf2txt.py-ow9.htmlw9.pdf pdf2txt.py-ow9.xmlw9.pdf |
Первая команда создаст документ HTML, в то время как вторая создаст XML. Вот скриншот того, что я получил, воспользовавшись HTML конверсией:
Как вы видите, конец выглядит не лучшим образом, но бывало и хуже. Получаемый на выходе XML очень подробный, так что я не смогу выложить его здесь. Однако, есть сниппет, который даст вам понимание того, как это выглядит:
XHTML
<pages>
<page id=»1″ bbox=»0.000,0.000,611.976,791.968″ rotate=»0″>
<textbox id=»0″ bbox=»36.000,732.312,100.106,761.160″>
<textline bbox=»36.000,732.312,100.106,761.160″>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»36.000,736.334,40.018,744.496″ size=»8.162″>F</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»40.018,736.334,44.036,744.496″ size=»8.162″>o</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»44.036,736.334,46.367,744.496″ size=»8.162″>r</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»46.367,736.334,52.338,744.496″ size=»8.162″>m</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»52.338,736.334,54.284,744.496″ size=»8.162″> </text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»54.284,736.334,56.230,744.496″ size=»8.162″> </text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»56.230,736.334,58.176,744.496″ size=»8.162″> </text
><text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»58.176,736.334,60.122,744.496″ size=»8.162″> </text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»60.122,732.312,78.794,761.160″ size=»28.848″>W</text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»78.794,732.312,87.626,761.160″ size=»28.848″>-</text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»87.626,732.312,100.106,761.160″ size=»28.848″>9</text>
<text></text>
</textline>
|
1 |
<pages> <page id=»1″bbox=»0.000,0.000,611.976,791.968″rotate=»0″> <textbox id=»0″bbox=»36.000,732.312,100.106,761.160″> <textline bbox=»36.000,732.312,100.106,761.160″> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»36.000,736.334,40.018,744.496″size=»8.162″>F</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»40.018,736.334,44.036,744.496″size=»8.162″>o</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»44.036,736.334,46.367,744.496″size=»8.162″>r</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»46.367,736.334,52.338,744.496″size=»8.162″>m</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»52.338,736.334,54.284,744.496″size=»8.162″></text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»54.284,736.334,56.230,744.496″size=»8.162″></text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»56.230,736.334,58.176,744.496″size=»8.162″></text ><text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»58.176,736.334,60.122,744.496″size=»8.162″></text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»60.122,732.312,78.794,761.160″size=»28.848″>W</text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»78.794,732.312,87.626,761.160″size=»28.848″>-</text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»87.626,732.312,100.106,761.160″size=»28.848″>9</text> <text></text> </textline> |