Представление данных корреляционного анализа
Содержание:
- Суть корреляционного анализа
- Регрессионный анализ в Excel
- Шесть тысяч четыреста пятьдесят три рубля шестьдесят три копейки
- Регрессионный анализ в Excel
- Корреляционная функция
- Расчет коэффициента корреляции
- Hard Reset средствами самой системы Android
- Прочитайте журнал событий
- Множественная корреляция, её коэффициент
- Критерии и методы
- КРИТЕРИЙ СПИРМЕНА
Суть корреляционного анализа
Предназначение корреляционного анализа сводится к выявлению наличия зависимости между различными факторами. То есть, определяется, влияет ли уменьшение или увеличение одного показателя на изменение другого.
Если зависимость установлена, то определяется коэффициент корреляции. В отличие от регрессионного анализа, это единственный показатель, который рассчитывает данный метод статистического исследования. Коэффициент корреляции варьируется в диапазоне от +1 до -1. При наличии положительной корреляции увеличение одного показателя способствует увеличению второго. При отрицательной корреляции увеличение одного показателя влечет за собой уменьшение другого. Чем больше модуль коэффициента корреляции, тем заметнее изменение одного показателя отражается на изменении второго. При коэффициенте равном 0 зависимость между ними отсутствует полностью.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Шесть тысяч четыреста пятьдесят три рубля шестьдесят три копейки
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционная функция
Для графического отображения полученных результатов применяют корреляционную функцию (КФ), являющуюся зависимостью коэффициента корреляции явления от временного сдвига (лага). Существует два вида КФ: классическая, или техническая, и интервальная (рис. 7 и рис. 8 соответственно). Классическая корреляционная функция для анализа ЭЭГ не подходит, т.к. при разных t анализу будут подлежать участки разной протяженности, а для сопоставимости коэффициентов корреляции это допустимо только в случае стационарности процессов, которые сохраняют свои свойства на всей протяженности.
Классическая корреляционная функция имеет недостатки:
- невозможность сопоставлять коэффициенты корреляции, которые были вычислены для фрагментов ЭЭГ с различной протяженностью, поскольку полученные коэффициенты будут иметь разные характеристики (т.к. ЭЭГ не является стационарным процессом)
- размер выборки может отличаться; величины на одном конце функции могут быть значимые, а на другом – нет.
Рисунок 7. Классическая, или техническая, корреляционная функция
При построении интервальной корреляционной функции на записи сигнала обращают внимание на корреляционный образец χ длиной Δt, от которого начинается эпоха анализа Т. Чтобы найти связь между явлениями χ при изменении t, необходим анализ равноразмерных участков γ, которые сдвинуты относительно χ на значение τ
(рис. 8)
Если сравнивать интервальную и классическую корреляционные функции, то можно заметить, что интервальная функция имеет несколько преимуществ:
- Используется чаще при выявлении задержек в ЭЭГ-сигнале;
- Повторение этапов высоких значений при сдвигах образца;
- Ее легко интерпретировать.
При исследовании интервальной корреляционной функции необходимо отметить, что высокие значения функции при автокорреляции – это возможное следствие возврата к исходному функциональному состоянию, а в случае кросскорреляционной функции – задержки передачи сигнала между отведениями.
Рисунок 8. Интервальная корреляционная функция
Наиболее чувствительный метод для поиска различий в ЭЭГ-сигналах – огибающая ЭЭГ, оценивающая меру синхронности или асинхронности изменений постсинаптических потенциалов в исследуемых отведениях (амплитуда сигнала повышается при одновременном изменении двух сигналов).
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
- В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
- Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
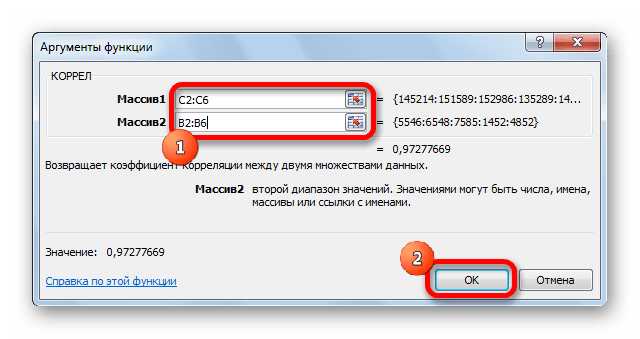
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.

Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
- В открывшемся окне перемещаемся в раздел «Параметры».
- Далее переходим в пункт «Надстройки».
- В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
- В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
- После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
- Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
- Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».

Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.

Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Hard Reset средствами самой системы Android
Прочитайте журнал событий
В июне 2020 года Microsoft исправила Windows 10 для защиты от уязвимости безопасности Bluetooth. Однако это привело к проблемам с подключением некоторых устройств Bluetooth.
Вы можете увидеть, влияет ли это на вас. Нажмите клавишу Windows + X и нажмите «Просмотр событий». Под сводкой административных событий разверните Ошибка и найдите следующее:
- Код события: 22
- Источник события : BTHUSB или BTHMINI
- Имя: BTHPORT_DEBUG_LINK_KEY_NOT_ALLOWED
- Текст сообщения о событии: Ваше устройство Bluetooth попыталось установить отладочное соединение. Стек Windows Bluetooth не разрешает отладочное соединение, пока оно не находится в режиме отладки.
Если вы видите это, Microsoft рекомендует связаться с производителем вашего устройства Bluetooth, чтобы узнать, сделали ли они патч. Если нет, вам может потребоваться купить новое устройство Bluetooth полностью.
Множественная корреляция, её коэффициент
Множественная корреляция — это вероятностная зависимость между одной величиной с
одной стороны, и одновременно несколькими другими ,
с другой стороны.
То есть, в отличие от парной корреляции, при которой
на изменения зависимой (результирующей) переменной влияет одна независимая (объясняющая) переменная,
при множественной корреляции независимых (объясняющих) переменных две или больше.
Цель корреляционного анализа в случае множественной корреляции — установить, есть ли зависимость между
переменными и насколько тесно связаны между собой зависимая переменная, с одной стороны, и независимые
переменные, с другой стороны, и зависят ли друг от друга независимые переменные .
Для того чтобы можно было бы применять модель множественной линейной регрессии, прежде, при анализе
множественной корреляции должны быть установлены следующие факты:
- зависимая переменная тесно зависит от независимых переменных (тесноту связи, как и в случае
парной корреляции, показывают ); - нет тесной зависимости между независимыми переменными.
Коэффициент множественной корреляции в случае двухфакторной корреляции рассчитывается по следующей формуле:
.
Коэффициенты множественной корреляции между зависимой переменной
и независимыми переменными
записываются в корреляционную матрицу:
Пример 1. Аналитик предприятия решил проверить факторы, которые
влияют на размер заработной платы сотрудников . Предварительно
в качестве объясняющих факторов выбраны: возраст сотрудника ,
стаж работы , оценка теста для приёма
на работу и число подчинённых
сотрудников . Случайно были выбраны
200 сотрудников, данные которых были обобщены. В результате была получена следующая корреляционная матрица:
| 1 | |||||
| -0,27 | 1 | ||||
| 0,78 | -0,63 | 1 | |||
| -0,83 | 0,47 | -0,89 | 1 | ||
| 0,65 | -0,46 | 0,17 | -0,21 | 1 |
Установить, какие переменные можно выбрать как независимые, для того, чтобы далее
можно было бы строить модель множественной регрессии.
Решение.
Корреляционная матрица показывает, что между переменными:
- и — слабая линейная связь: -0,27;
- и — средне тесная положительная линейная связь: 0,78;
- и — тесная отрицательная линейная связь: -0,83;
- и — средне тесная линейная связь: 0,65;
- и — тесная отрицательная линейная связь: -0,89;
- и — слабая линейная связь: 0,17;
- и — слабая линейная связь: -0,21.
Таким образом, не следует включать в число переменных, влияющих на размер заработной
платы возраст сотрудников . Так как
между независимыми переменными и
установлена тесная отрицательная связь,
не включаем в число переменных, влияющих на размер заработной платы стаж работы .
Выбираем в качестве независимых переменных оценку теста для приёма
на работу и число подчинённых
сотрудников .
Чтобы установить тесноту связи между заработной платой сотрудников ,
с одной стороны, и оценкой теста для приёма
на работу и числом подчинённых
сотрудников , с другой стороны,
вычислим коэффициент множественной (двухфакторной) корреляции:
Таким образом, между заработной платой сотрудников, с одной стороны, и
оценкой теста для приёма на работу и числом подчинённых, с другой стороны, существует тесная линейная
связь.
Как показывает пример выше, в исследованиях поведения человека,
как и во многих других направлениях, важно установить, какие факторы из многих действительно влияют на
результат при учете влияния всех остальных факторов
Критерии и методы
КРИТЕРИЙ СПИРМЕНА
Коэффициент ранговой корреляции Спирмена – это непараметрический метод, который используется с целью статистического изучения связи между явлениями. В этом случае определяется фактическая степень параллелизма между двумя количественными рядами изучаемых признаков и дается оценка тесноты установленной связи с помощью количественно выраженного коэффициента.
Чарльз Эдвард Спирмен
1. История разработки коэффициента ранговой корреляции
Данный критерий был разработан и предложен для проведения корреляционного анализа в 1904 году Чарльзом Эдвардом Спирменом, английским психологом, профессором Лондонского и Честерфилдского университетов.
2. Для чего используется коэффициент Спирмена?
Коэффициент ранговой корреляции Спирмена используется для выявления и оценки тесноты связи между двумя рядами сопоставляемых количественных показателей. В том случае, если ранги показателей, упорядоченных по степени возрастания или убывания, в большинстве случаев совпадают (большему значению одного показателя соответствует большее значение другого показателя — например, при сопоставлении роста пациента и его массы тела), делается вывод о наличии прямой корреляционной связи. Если ранги показателей имеют противоположную направленность (большему значению одного показателя соответствует меньшее значение другого — например, при сопоставлении возраста и частоты сердечных сокращений), то говорят об обратной связи между показателями.
- Коэффициент корреляции Спирмена обладает следующими свойствами:
- Коэффициент корреляции может принимать значения от минус единицы до единицы, причем при rs=1 имеет место строго прямая связь, а при rs= -1 – строго обратная связь.
- Если коэффициент корреляции отрицательный, то имеет место обратная связь, если положительный, то – прямая связь.
- Если коэффициент корреляции равен нулю, то связь между величинами практически отсутствует.
- Чем ближе модуль коэффициента корреляции к единице, тем более сильной является связь между измеряемыми величинами.
3. В каких случаях можно использовать коэффициент Спирмена?
В связи с тем, что коэффициент является методом непараметрического анализа, проверка на нормальность распределения не требуется.
Сопоставляемые показатели могут быть измерены как в непрерывной шкале (например, число эритроцитов в 1 мкл крови), так и в порядковой (например, баллы экспертной оценки от 1 до 5).
Эффективность и качество оценки методом Спирмена снижается, если разница между различными значениями какой-либо из измеряемых величин достаточно велика. Не рекомендуется использовать коэффициент Спирмена, если имеет место неравномерное распределение значений измеряемой величины.
4. Как рассчитать коэффициент Спирмена?
Расчет коэффициента ранговой корреляции Спирмена включает следующие этапы:
- Сопоставить каждому из признаков их порядковый номер (ранг) по возрастанию или убыванию.
- Определить разности рангов каждой пары сопоставляемых значений (d).
- Возвести в квадрат каждую разность и суммировать полученные результаты.
- Вычислить коэффициент корреляции рангов по формуле:
Определить статистическую значимость коэффициента при помощи t-критерия, рассчитанного по следующей формуле:
5. Как интерпретировать значение коэффициента Спирмена?
При использовании коэффициента ранговой корреляции условно оценивают тесноту связи между признаками, считая значения коэффициента меньше 0,3 — признаком слабой тесноты связи; значения более 0,3, но менее 0,7 — признаком умеренной тесноты связи, а значения 0,7 и более — признаком высокой тесноты связи.
Также для оценки тесноты связи может использоваться шкала Чеддока:
xy
Теснота (сила) корреляционной связи
менее 0.3
слабая
от 0.3 до 0.5
умеренная
от 0.5 до 0.7
заметная
от 0.7 до 0.9
высокая
более 0.9
весьма высокая
Статистическая значимость полученного коэффициента оценивается при помощи t-критерия Стьюдента. Если расчитанное значение t-критерия меньше табличного при заданном числе степеней свободы, статистическая значимость наблюдаемой взаимосвязи — отсутствует. Если больше, то корреляционная связь считается статистически значимой.